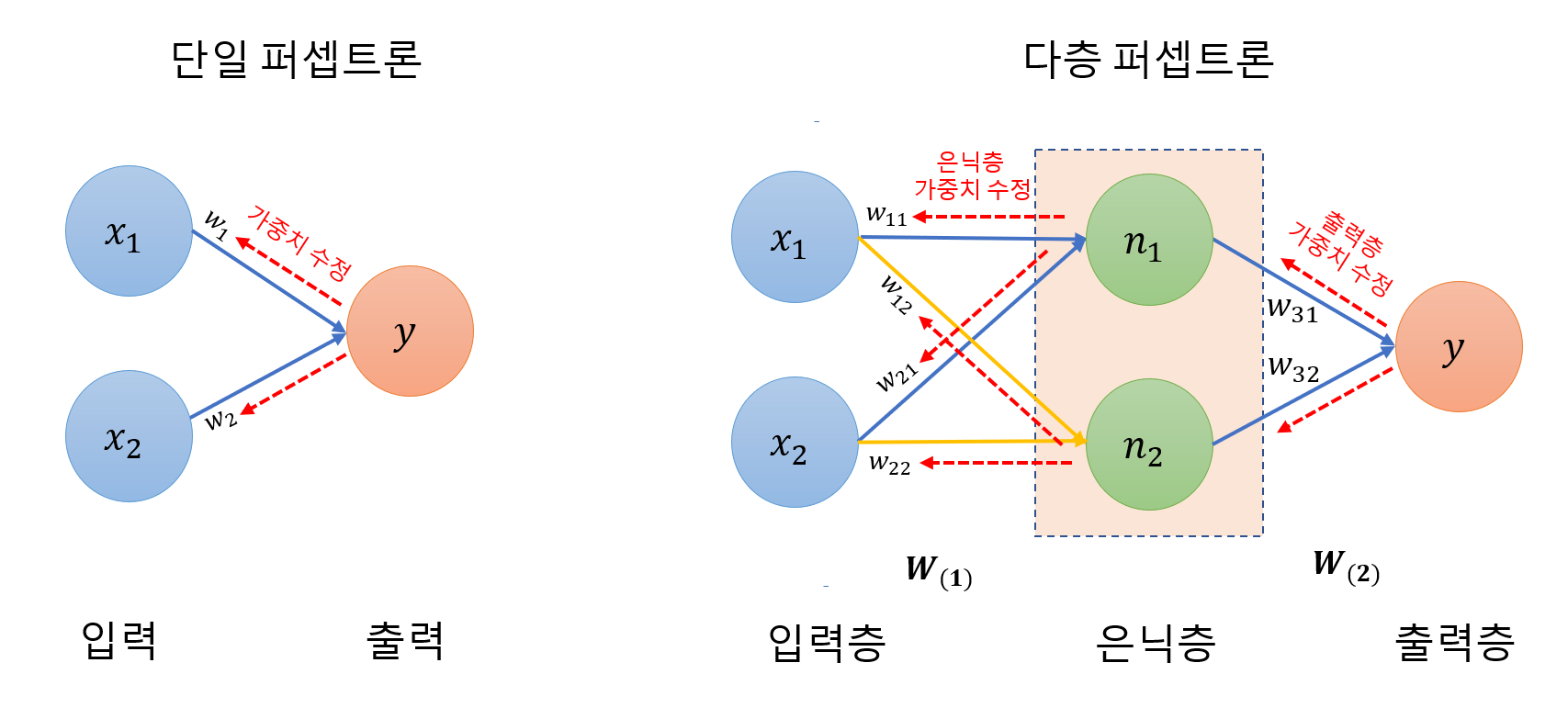
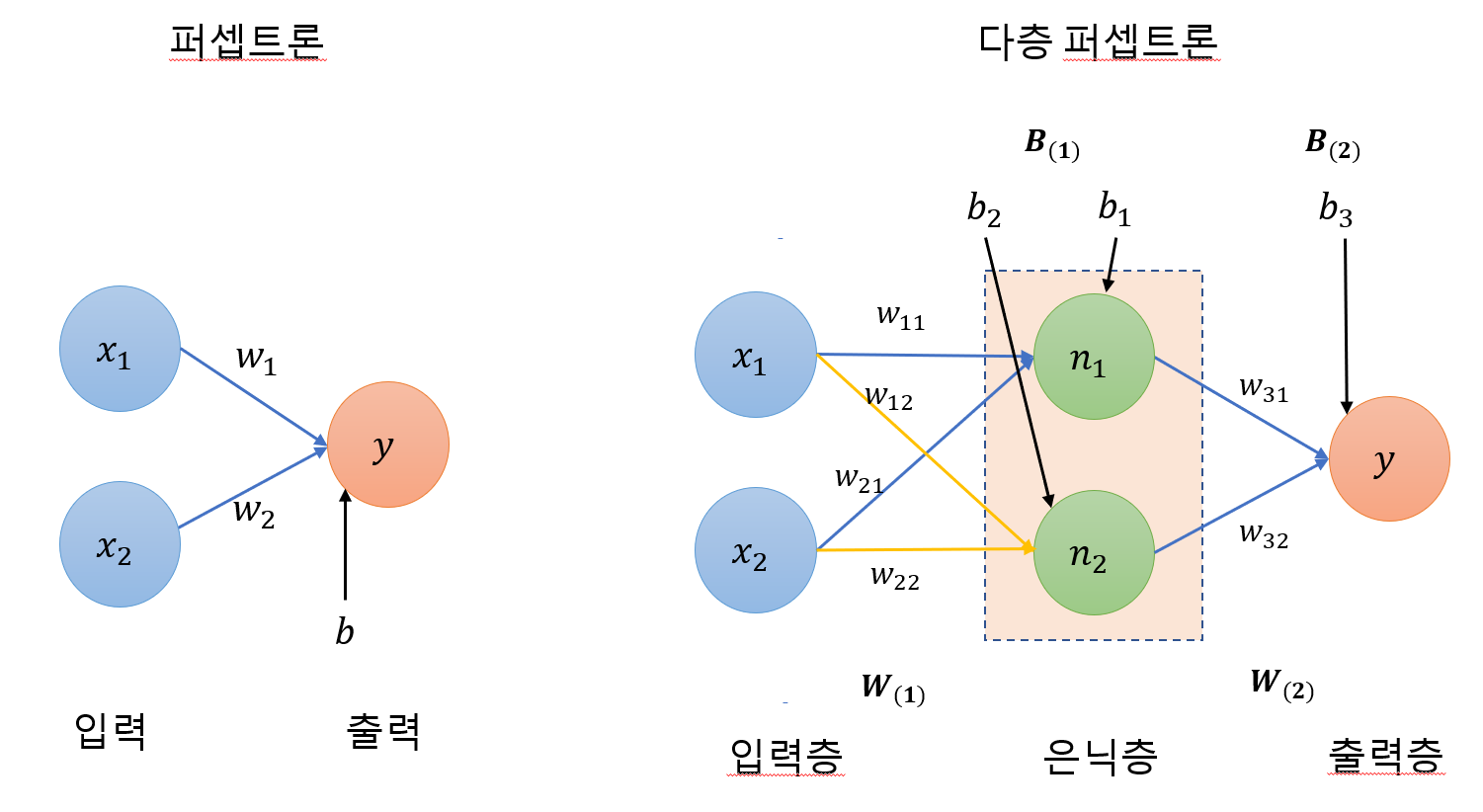
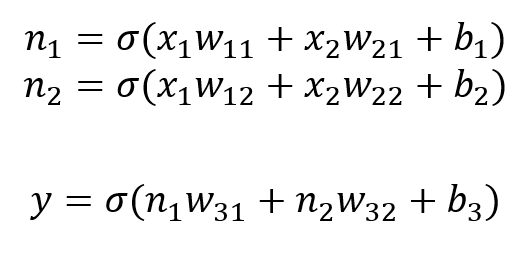여기서는 모델이 수행되는 과정에서는 에러가 없었으나, 최종 결과가 loss: NaN, accuracy:NaN, mae:NaN 등으로 나오는 경우, 필자가 찾아낸 문제해결 법이다.
지금까지 2가지 경우에 대해서 경험하였고,다음과 같이 해결할 수 있다.
1. 입력 데이터에 NA 가 들어있는 경우
이때 아래와 같이 데이터 셋에서 NA를 제거해 준 다음 사용하면 된다.
> data.set <- na.omit(<INPUT DATA>)
> str(data.set)
2. 활성화 함수 선택이 문제인 경우
1번으로 해결되지 않을 때, layer_dense 내activation함수를 "softmax"에서 "relu"로 바꾸면 된다. single output 인 경우, softmax를 사용하면 이런 현상이 발생할 수 있다. 여기(https://github.com/keras-team/keras/issues/2134) 내용의 댓글들을 참고하시오.
책이나 사이트에 공개된 잘 만들어진 예제를 이용해서, 자신의 데이터에 바로 적용할 때, 필자와 같은 왕초보들은 항상, as always, as usual, 필연적으로, 반드시, 운명적으로, .... 한방에 작동하지 않고 여러가지 문제들로 인해 머리가 지끈지끈 아픈 상황과 문제가 발생할 수 있다. 아니, 발생한다. 하나하나 잡아보자.
딥러닝 책 등에서 제공된 예제 파일들은 모두 Keras 등의 패키지 내에 포함된 예제 파일들이다. 그래서 실제 내가 만든 .csv 파일을 읽어 들이는데, 입력 포맷이 맞지 않아 헤맬 수 있다. 이런 경우, 모델이 잘 돌아가지만, input_data 값이 없다는 에러가 발생할 수 있다.
아래와 같이 sampling 하면, 일반 책에서 사용하는 예제 파일을 읽어들이는 포맷으로 쉽게 변환된다. 아래는 13개 컬럼으로 구성된 데이터 셋의 경우의 예임.
> set.seed(1)
# sample 함수는 수행할 때 마다 다른 난수를 추출하기 때문에 난수를 고정시켜 같은 값이 나오도록 하기 위함이다.
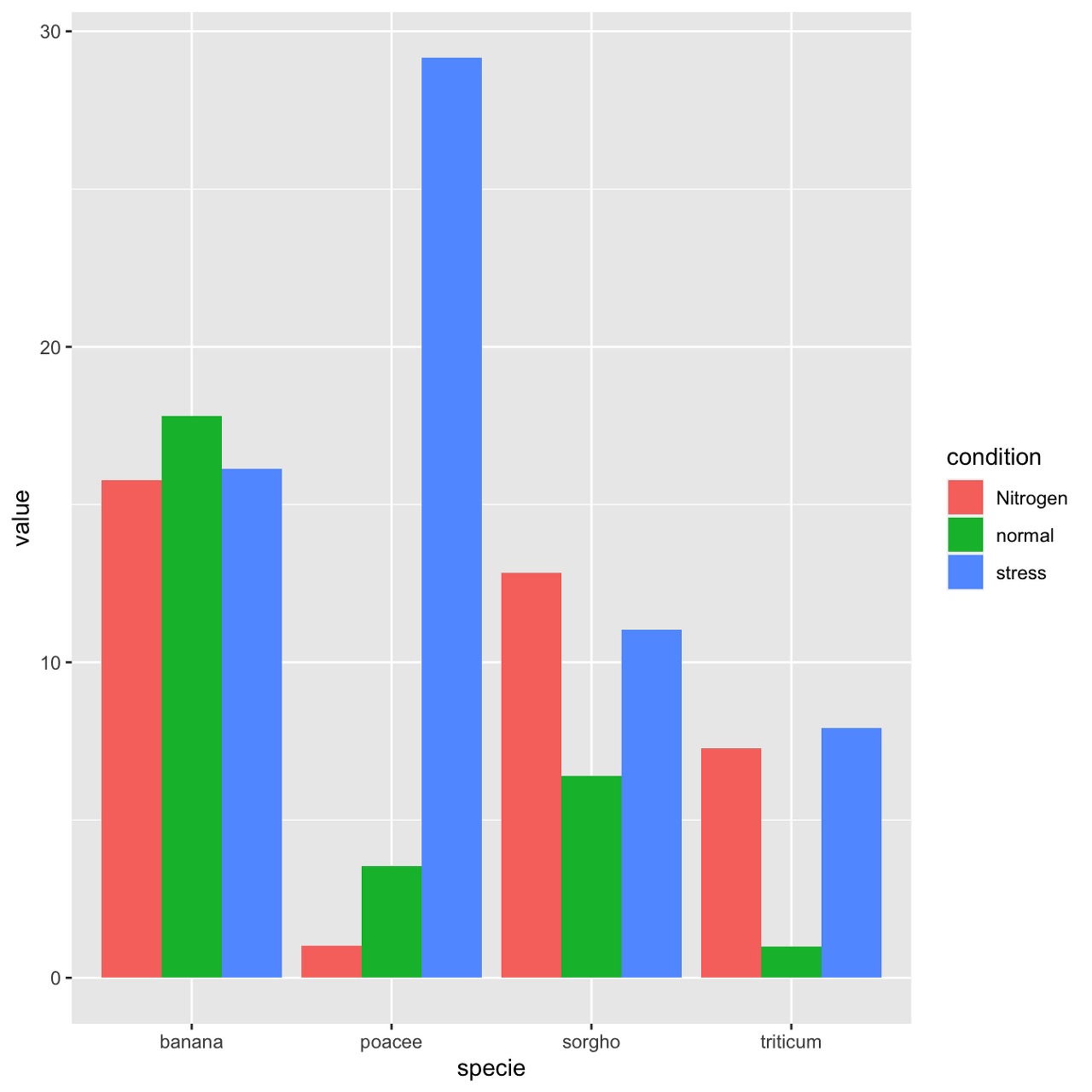
A grouped barplot display a numeric value for a set of entities split in groups and subgroups. Before trying to build one, check how to make abasic barplotwithRandggplot2.
A few explanation about the code below:
input dataset must provide 3 columns: the numeric value (value), and 2 categorical variables for the group (specie) and the subgroup (condition) levels.
in theaes()call, x is the group (specie), and the subgroup (condition) is given to thefillargument.
in thegeom_bar()call,position="dodge"must be specified to have the bars one beside each other.
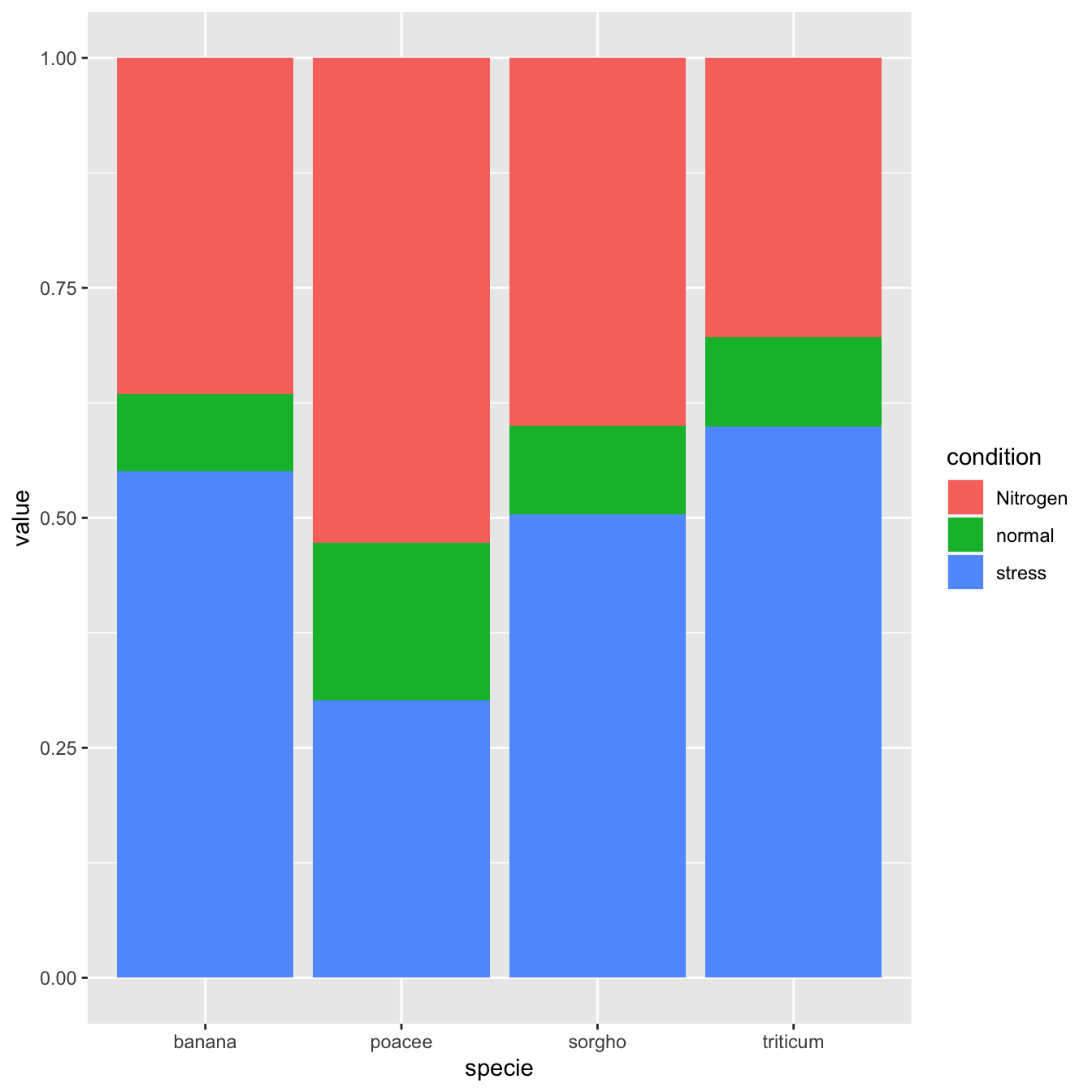
Once more, there is not much to do to switch to a percent stacked barplot. Just switch toposition="fill". Now, the percentage of each subgroup is represented, allowing to study the evolution of their proportion in the whole.