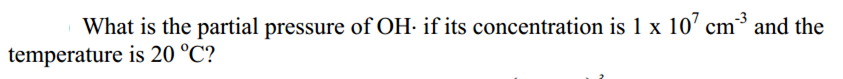MNIST 데이터베이스 (Modified National Institue of Standards and Technology database) 손글씨 이미지 데이터셋
0에서 9까지 10가지로 분류될 수 있는 손글씨 숫자 이미지 70,000개
각 이미지는 28×28 픽셀로 구성
각 픽셀은 아래와 같이 0~255 사이의 숫자 행렬로 표현됩니다.
[[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
60,000개의 이미지는 훈련 (Training) 에 사용
10,000개의 이미지는 테스트 (Test) 에 사용
코드 1. tensorflow 불러오기 # Tf를 쓰면 무려 Mnist 데이터를 다운받지 않아도 됨.
>>> import tensorflow as tf
2. MNIST 데이터셋 불러오기 (import) # Tf에서는 train / test set을 자동으로 나눔.
>>> mnist = tf.keras.datasets.mnist
3. 데이터 전처리 # 딥러닝은 0~1 사이로 input 데이터의 범위를 해줘야 원활한 학습이 가능.
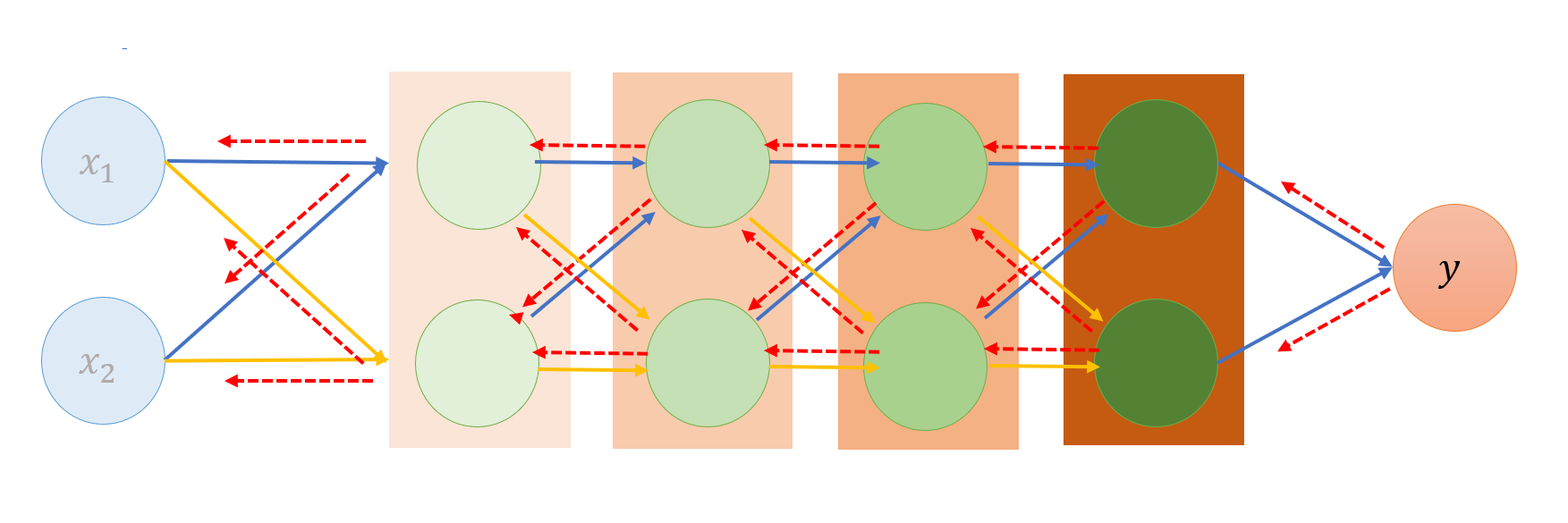
4. 모델구성 # tf.keras.models.Sequential()을 이용해서 인공신경망 모델을 구성
>>> model = tf.keras.models.Sequential([ 입력층 (Input layer)에서 Flatten()을 이용해서 28×28 픽셀의 값을 784개의 1차원 배열로 변환
... tf.keras.layers.Reshape((28, 28, 1)),
# 각 층은 512개와 10개의 인공 뉴런 노드를 갖고 활성화 함수 (activation function)로는 각각 ReLU (tf.nn.relu)와 소프트맥스 (tf.nn.softmax) 사용.
5. 모델 컴파일 >>> model.compile(optimizer='adam',
6. 모델 훈련 >>> model.fit(x_train, y_train, epochs=5)
7. 모델 평가 # model.evaluate()를 이용해서 10,000개의 테스트 샘플에 대해 손실 (loss)과 정확도 (accuracy)를 평가
>>> test_loss , test_acc = model . evaluate ( x_test , y_test )
>>> print( '테스트 정확도:' , test_acc )
# Matplotlib을 이용해서 에포크에 따른 정확도 (accuracy)와 손실 (loss) 값을 확인
>>> loss, accuracy = [], []
>>> fori in range ( 10 ):
... model. fit ( x_train , y_train , epochs = 1 )
... l oss. append ( model . evaluate ( x_test , y_test )[ 0 ])
... a ccuracy. append ( model . evaluate ( x_test , y_test )[ 1 ])
>>> print( accuracy )
코드 (copy & paste & run) import tensorflow as tf