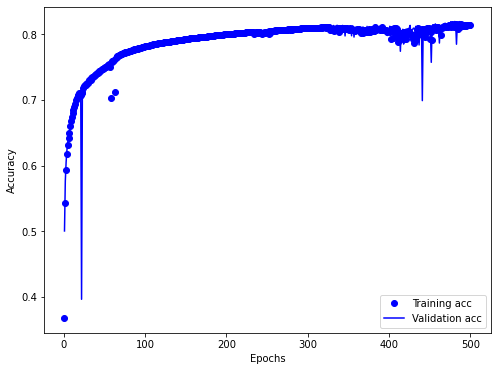
모델링 평가자료
1차 데이터셋: qc_ASOS 데이터 (2-3시간 차이)
2차 데이터셋: mrg_ASOS_AAOS 데이터 (1-2시간 차이) 오직 y=flag
3차 데이터셋: mrg_ASOS_AAOS 데이터 (1-2시간 차이) x에 vis_log 를 추가하고 y=flag
데이터셋 주의 사항
vis_10m는 제외해야 된다.
오로지 flag로만 비교할때 보다, vis_log가 남아 있을 때 결과가 약간 더 향상되는 경우가 있다.
코드 예제 - 의사결정 나무
#의사결정 나무
## 데이터 학습
from sklearn import tree
clf_tree = tree.DecisionTreeClassifier(random_state=0)
clf_tree.fit(X_train_std, y_train)
## 데이터 예측
pred_tree = clf_tree.predict(X_test_std)
print(pred_tree)
## 모델 스코어 평가
get_clf_eval(y_test, pred_tree)
## 분류 리포트 확인
from sklearn.metrics import classification_report
class_report = classification_report(y_test, pred_tree)
print(class_report)
분류 리포트 (2차 결과)
의사결정 나무
| 1차 2차 > 3차
---------------------------
precision | 1.0
recall | 0.50
f1-score | 0.53
support | 0.52
2차
precision recall f1-score support
0.0 0.99 0.99 0.99 10198
1.0 0.81 0.81 0.81 324
accuracy 0.99 10522
macro avg 0.90 0.90 0.90 10522
weighted avg 0.99 0.99 0.99 10522
3차
precision recall f1-score support
0.0 0.99 0.99 0.99 10198
1.0 0.81 0.80 0.80 324
accuracy 0.99 10522
macro avg 0.90 0.90 0.90 10522
weighted avg 0.99 0.99 0.99 10522
랜덤포레스트
| 1차 2차 < 3차
---------------------------
precision | 1.0
recall | 1.00
f1-score | 0.09
support | 0.16
2차
precision recall f1-score support
0.0 0.99 1.00 1.00 10198
1.0 1.00 0.70 0.82 324
accuracy 0.99 10522
macro avg 1.00 0.85 0.91 10522
weighted avg 0.99 0.99 0.99 10522
3차
precision recall f1-score support
0.0 0.99 1.00 1.00 10198
1.0 1.00 0.74 0.85 324
accuracy 0.99 10522
macro avg 0.99 0.87 0.92 10522
weighted avg 0.99 0.99 0.99 10522
나이브 베이즈
| 1차 2차 < 3차
---------------------------
precision | 1.0
recall | 1.0
f1-score | 0.09
support | 0.16
2차
precision recall f1-score support
0.0 0.99 1.00 1.00 10198
1.0 1.00 0.70 0.82 324
accuracy 0.99 10522
macro avg 1.00 0.85 0.91 10522
weighted avg 0.99 0.99 0.99 10522
3차
precision recall f1-score support
0.0 0.99 1.00 1.00 10198
1.0 1.00 0.74 0.85 324
accuracy 0.99 10522
macro avg 0.99 0.87 0.92 10522
weighted avg 0.99 0.99 0.99 10522
에이다 부스트
| 1차 2차 < 3차
---------------------------
precision | 1.0
recall | 0.75
f1-score | 0.54
support | 0.63
2차
precision recall f1-score support
0.0 0.99 1.00 1.00 10198
1.0 0.93 0.79 0.85 324
accuracy 0.99 10522
macro avg 0.96 0.89 0.93 10522
weighted avg 0.99 0.99 0.99 10522
3차
precision recall f1-score support
0.0 0.99 1.00 1.00 10198
1.0 0.93 0.82 0.87 324
accuracy 0.99 10522
macro avg 0.96 0.91 0.93 10522
weighted avg 0.99 0.99 0.99 10522
그레디언트 부스트 (시간 걸림)
| 1차 2차 > 3차
---------------------------
precision | 1.0
recall | 0.38
f1-score | 0.03
support | 0.06
2차
precision recall f1-score support
0.0 0.99 1.00 1.00 10198
1.0 0.92 0.83 0.87 324
accuracy 0.99 10522
macro avg 0.96 0.91 0.94 10522
weighted avg 0.99 0.99 0.99 10522
3차
precision recall f1-score support
0.0 0.99 1.00 1.00 10198
1.0 0.92 0.81 0.86 324
accuracy 0.99 10522
macro avg 0.96 0.90 0.93 10522
weighted avg 0.99 0.99 0.99 10522
스태킹
| 1차 2차 = 3차.
---------------------------
precision | 1.0
recall | 0.70
f1-score | 0.56
support | 0.62
2차
precision recall f1-score support
0.0 0.99 1.00 1.00 10198
1.0 0.96 0.77 0.85 324
accuracy 0.99 10522
macro avg 0.98 0.88 0.92 10522
weighted avg 0.99 0.99 0.99 10522
3차
precision recall f1-score support
0.0 0.99 1.00 1.00 10198
1.0 0.96 0.77 0.85 324
accuracy 0.99 10522
macro avg 0.98 0.88 0.92 10522
weighted avg 0.99 0.99 0.99 10522