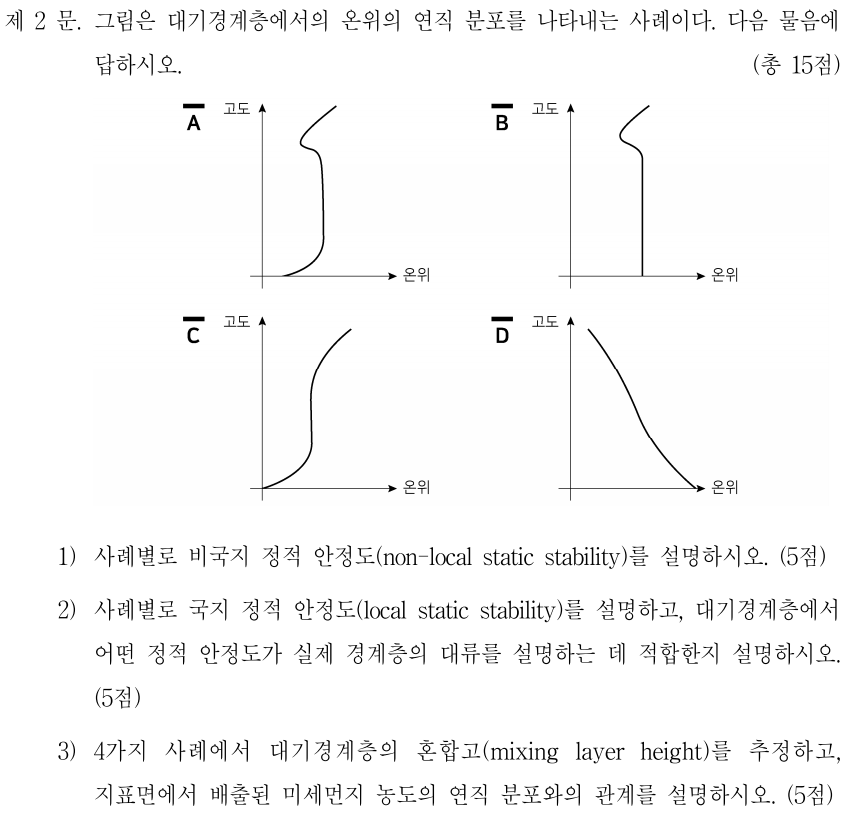
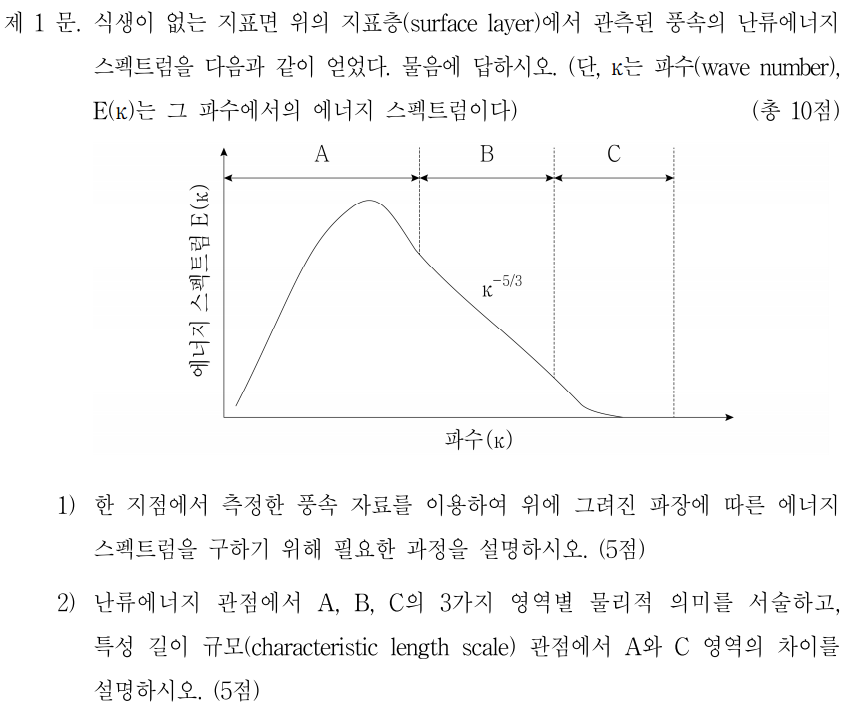
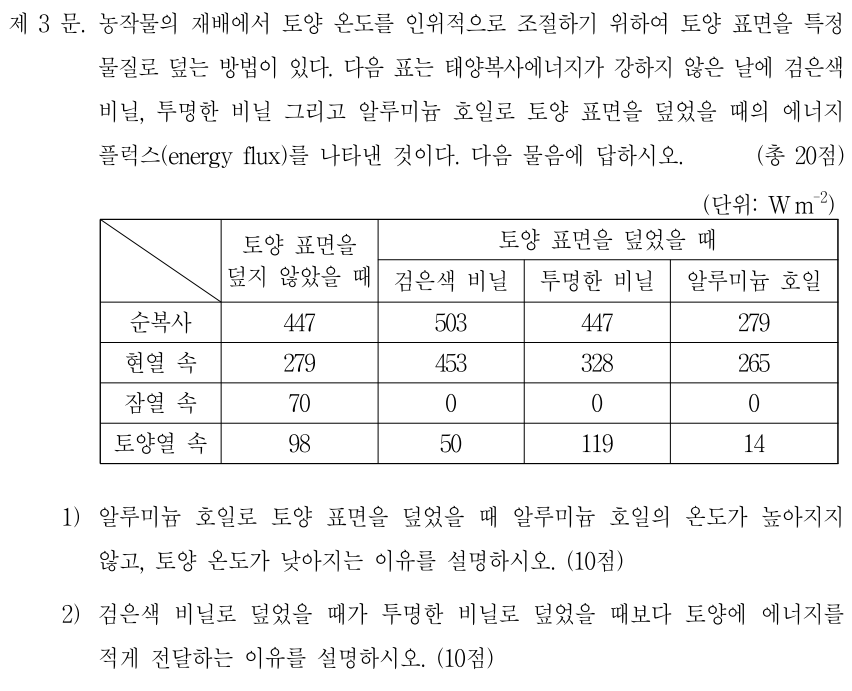
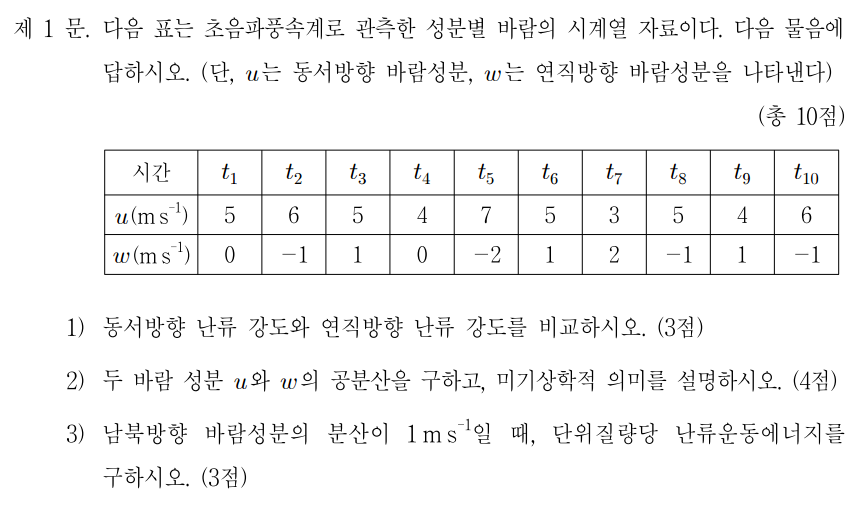
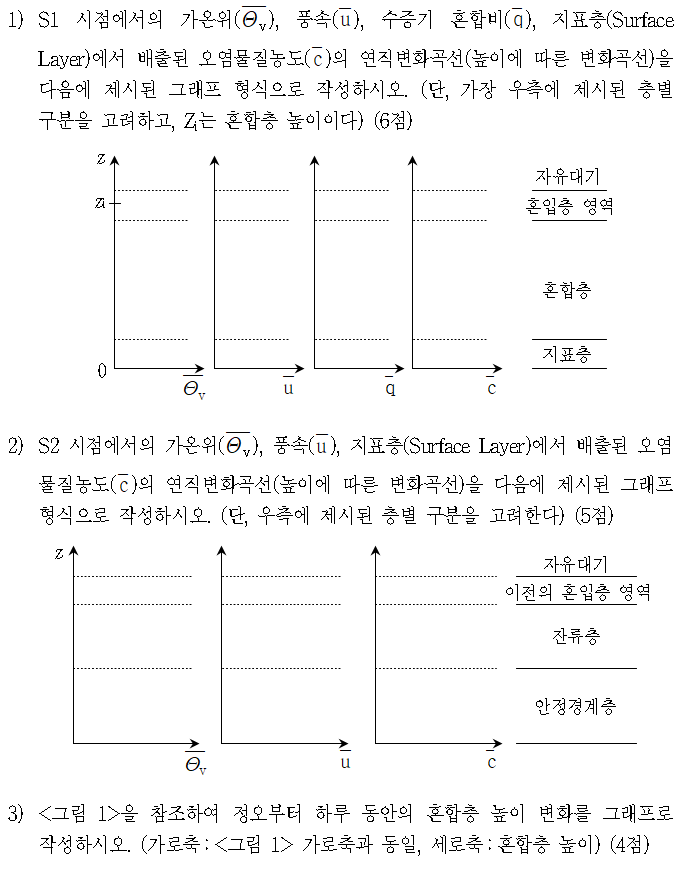
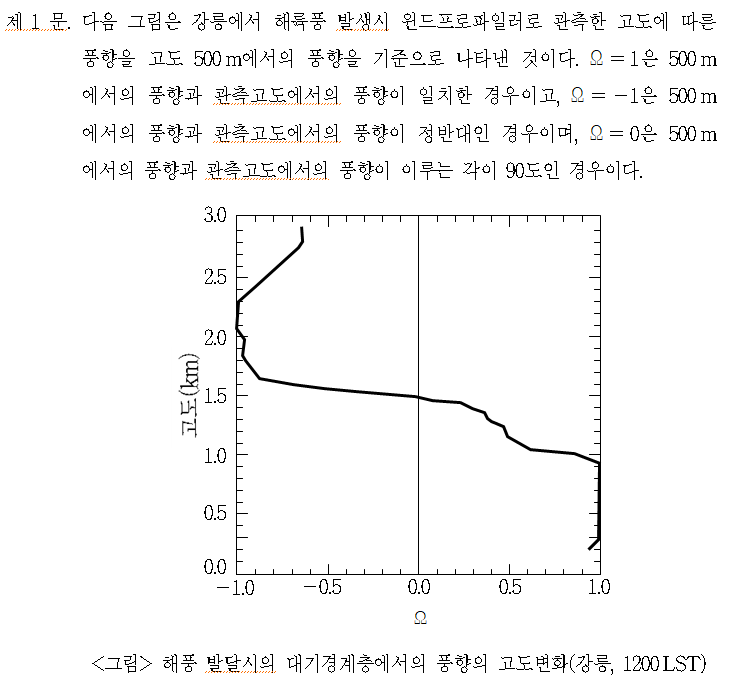
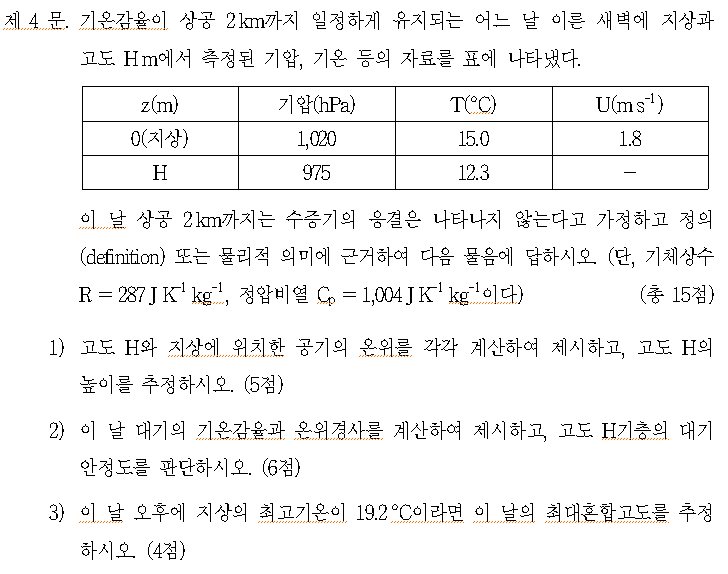
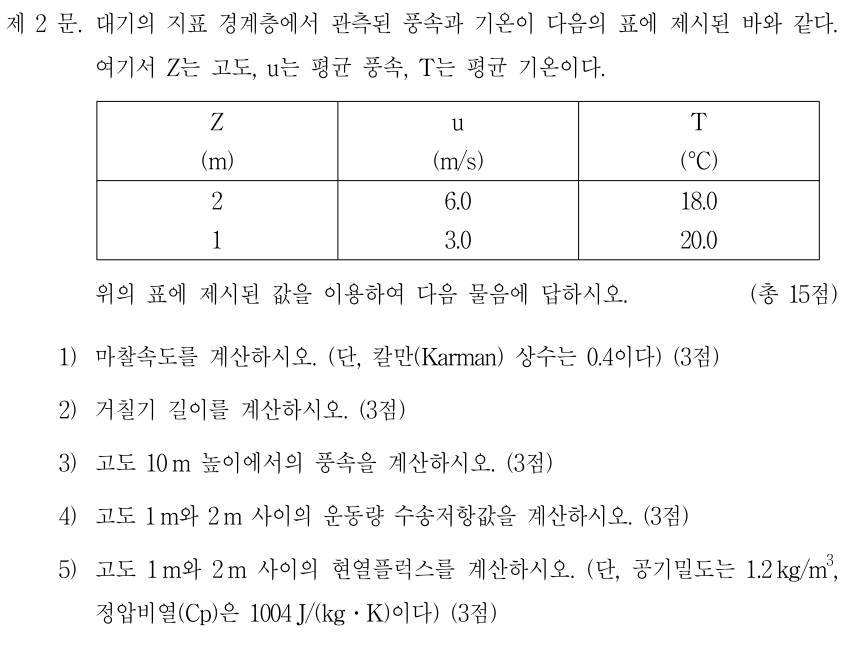
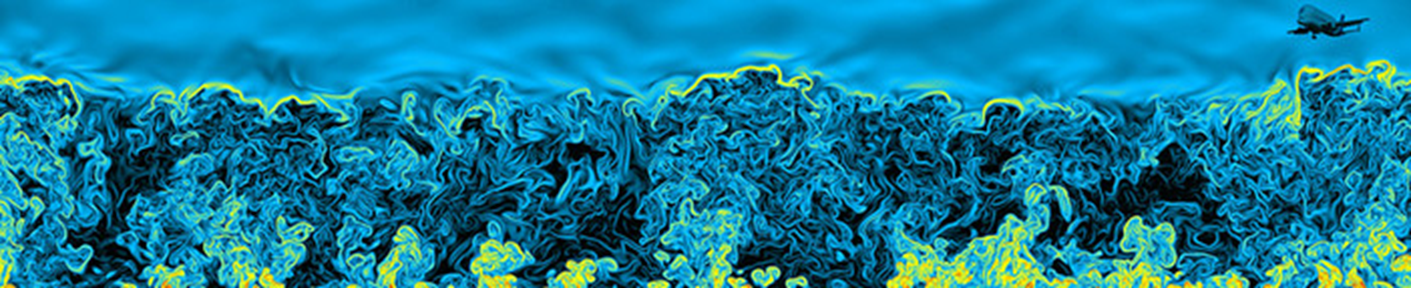
아래 그림: Vertical cross-section showing the distinct nature of the turbulent boundary layer, filled with chaotic motions of many different scales, and the upper troposphere, characterized by gentle undulations. The color indicates the magnitude of the local variation of the density field, increasing from black to yellow. Simulation performed by J. R. Garcia using 5120_5120_840 grid points. (The plane on the top right corner is included for illustration purposes and it is not part of the simulations.)
이 층에서는 momentum, heat, mass의 상당한 교환이 발생 (대기물리에서의 모멘텀)
속도, 온도, 질량 농도가 급격하게 변한다.
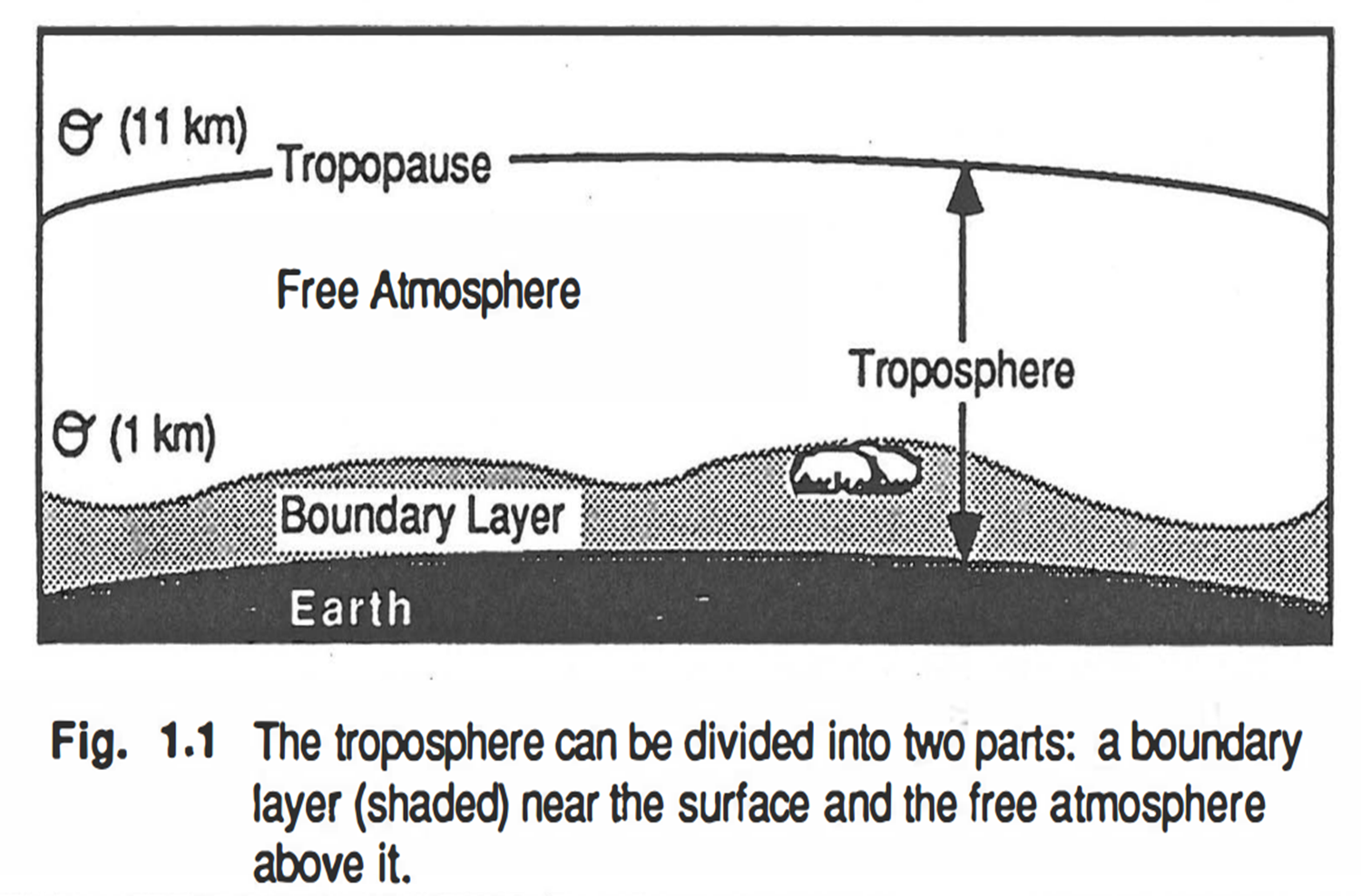
Planetary Boundary Layer (대기 경계층)
수 시간~ 약 하루 정도 시간 규모에서 대기-지표 사이의 상호작용의 결과로 형성
지표면 마찰, 가열 등의 영향은 난류 수송(turbulent transfer)나 혼합(mixing)에 의해 즉시 전체 PBL에 전달됨.
PBL = surface layer (지표층) + outer layer (바깥층)
연직 범위:
~ 1km 정도 (중립일때)
시간에 따라서 변동. 이른 아침에 <100m , 오후에 수 km 까지 변동.
수평 범위:
수십 m ~ 수 km
PBLH (Planetary Boundary Layer Height)
PBLH변동은 중규모와 종관 규모 시스템과 연관있다.
PBLH가 낮아지는 경우:
침강(하강운동)과 고기압에 의한 하층 수평 발산이 일어나는 경우 PBL은 얇아진다.
PBLH가 높아지는 경우:
구름 발달과 연관된 저기압과 관련되면 PBLH가 높아진다.
일반적으로 구름 하단을 PBL top 으로 간주 (Ceilometer 로 측정)
출처: Stull (1988)
대기 오염의 관점에서 PBL
대기 오염 물질이 PBL 내에서 혼합되는 층의 두께 (mixing depth)를 말한다.
일반적으로 free atmosphere 보다 훨씬 오염이 심각 (aircraft로 관측)
유체역학 도시 기상학적 관점에서의 PBL
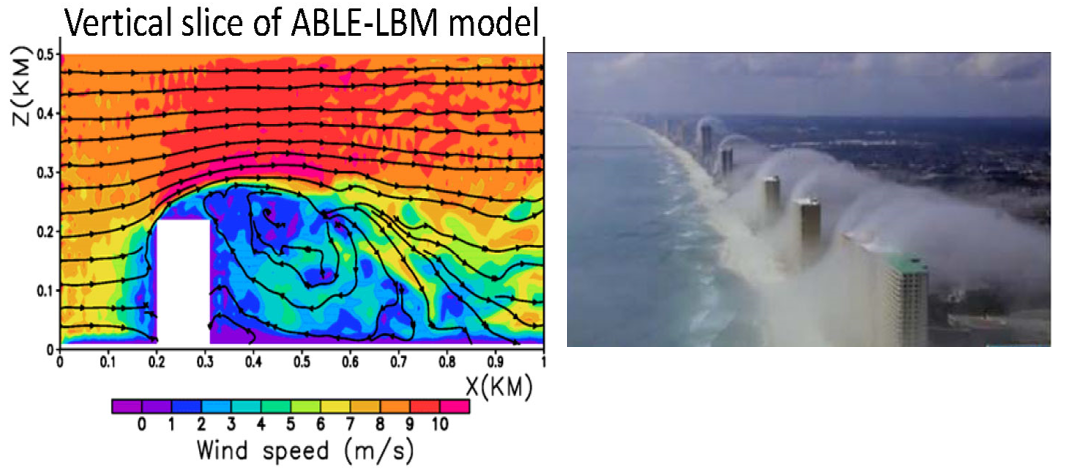
그림 4. Fine-scale turbulent flows over bulings: The ABLE-LBM modeling results (left panel) and the building generated lee-wakes due to colder temperature near building caused by water vapor condensation.
아래 그림과 같이 대기 규모(scale) 스펙트럼의 가장 낮은 끝단에서의 대기 현상과 과정을 다루는 기상학의 한 분야이다.
미기상학의 연구 대상은 대기 지표층 (surface layer)과 대기 경계층의 5 - 10% 높이에 해당하는 약 0.5 - 2km 깊이를 포함.
이 영역은 인간이 살아가는 환경이므로 대단히 중요.
지표면 마찰에 의해서 직접 영향을 받는 얕은 층으로 atmospheric boundary layer (ABL) 또는 planetary boundary layer (PBL)이라고 한다. 용어 정리
그림 1. Schematic spectrum of wind speed near the ground estimated from a study of Van der Hoven (1957). (출처: Stull 1988)
미기상학의 연구 대상
대기 경계층에서 발생하거나 지배받는 대기 현상에 한정
대기와 지표면간의 에너지, 질량, 운동량 교환
기상 변수들의 연직분포
난류
1. 바람,기온, 습도, 미량기체의 농도 등의 연직분포와 지표근처에서의 에너지 교환.
2. 대기와 지표면 상호간에 heat (energy), mass, momentum 의 교환.
지표근처의 에너지 수지 (budget)는 지표-대기-태양 시스템 에 포함되는 에너지 교환의 중요한 특징.
3. 기상변수의 단시간 평균 외에도 난류 섭동 (turbulence fluctuation) 의 통계학.
지표-대기 간 에너지 교환과 관련해서 중요.
대류운, 토네이도 같은 현상은 그 역학이 mesoscale과 macroscale 날씨 시스템에 영향에 의해 지배되기 때문에, 미기상학 분야에서는 제외.
미기상학의 중요성
난류 전달과정
PBL을 통한 질량,열,운동량의 교환작용
대기질은 PBL난류의 혼합능력에 의존
국지기상의 발달과 소멸에 큰 영향을 미침. 저/고기압 지역 내의 하층 수렴/발산에 영향을 미침
대기의 운동에너지는 난류에 의해서 연직적으로 소산됨.
미기상학과 미기후학
공통점: 지표면 부근에서 발생하는 대기 현상을 다룸
차이점: 기상변수들을 평균(적분)하는 시간이 다름 (단기간 vs. 장기간 평균 및 변동)
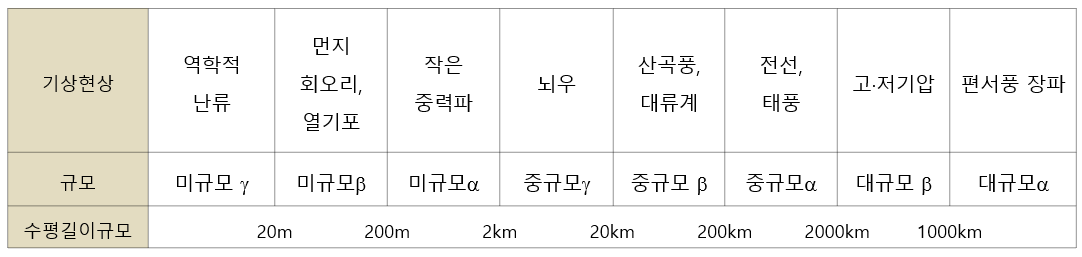
대기 운동 규모 (크기, scale) 분류
수평규모: 수 mm ~ 지구 둘레 크기 까지
연직규모: 지표면~ 전체 대기높이 까지
시간규모: <1초 ~ 몇 년
이를 기준으로, 지난 50년 동안 미규모 (microscale), 중규모(mesoscale), 대규모(macroscale) 또는 국지규모 (local), 지역규모(regional), 지구규모(global) 로 대기 규모의 스펙트럼을 나누어 연구되어 왔음 (그림 2 참조)
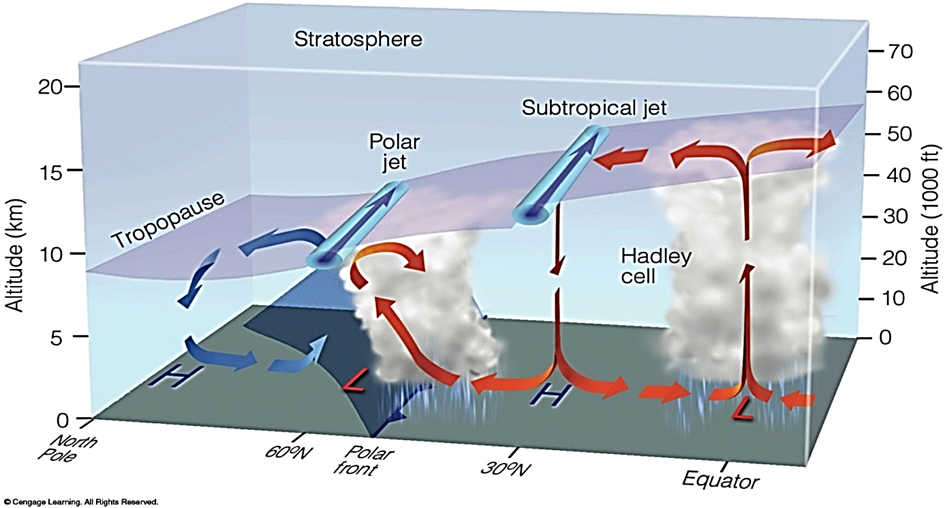
3-6일의 주파수, 수천 km (Rossby wave) 의 공간규모, 즉 대기순환규모
수초-수분의 시간간격은 micro-turbulence 규모에서의 에너지와 물질 교환과 관련됨.
그림 2. Typical time and space orders of magnitude for micro and mesoscales.
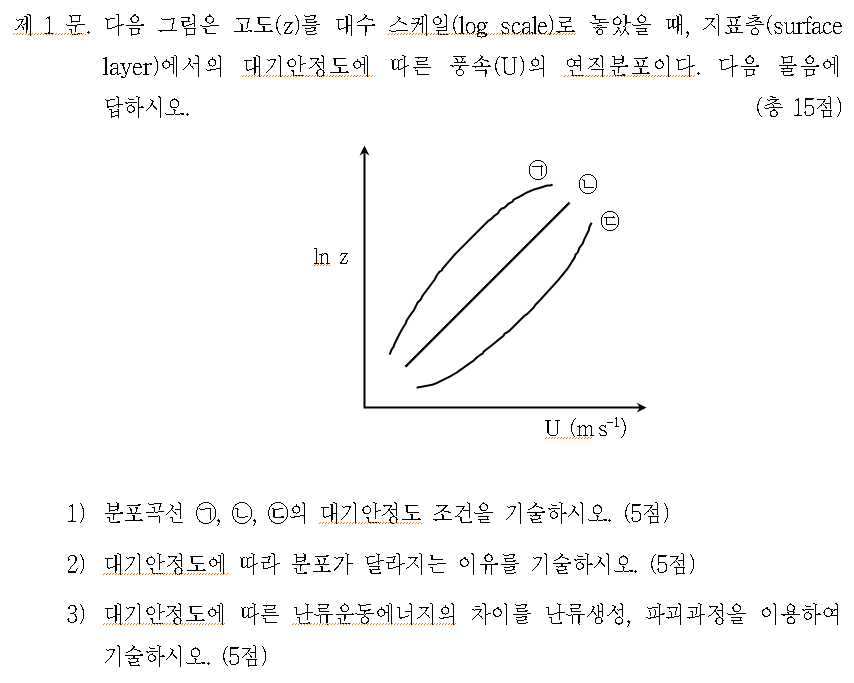
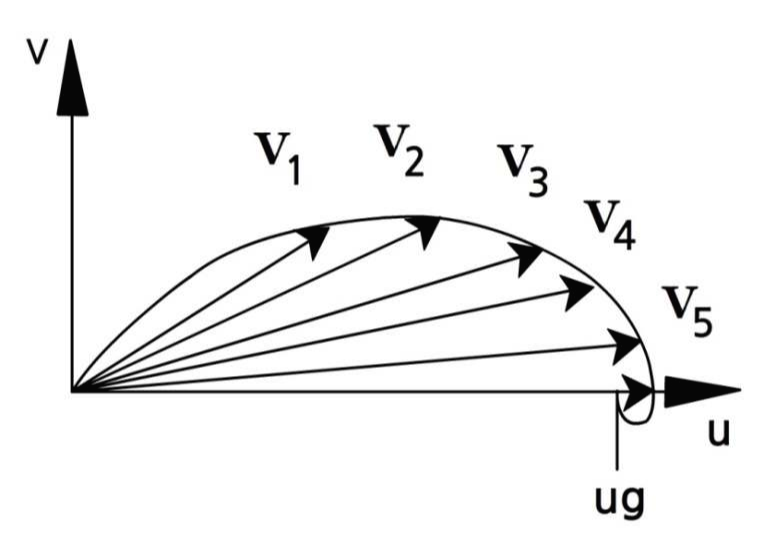
경계층 대기는 중립상태이고, 수평온도경도 및 연직속도가 존재하지 않는다고 가정하면, 경계층 내의 이론적 풍향 및 풍속 프로파일을 유추할 수 있다. 이러한 프로파일은 1890년대 V. W. Ekman에 의한 해양 상층부에서의 흐름의 연구로 부터 처음으로 얻어 졌고, 그 후 대기 경계층에 응용되어져 왔다.
지표 바람은 등압선에 대해 45° 각도로 저기압 쪽으로 불고, 상공으로 갈수록 마찰력이 감소하여 풍속이 증가하고, 북반구(남반구)에서는 시계(반시계) 방향으로 바뀌면서 나선형이 된다. 이것을 에크만 나선이라 한다(그림). 그림의 벡터는 V1, V2, V3... 순으로 고도가 높아진다. 또한, 고도에 따라 등압선과 이루는 각이 작아지고, 마찰의 영향을 거의 받지 않는 높이에 이르러서는 등압선과 나란하게 부는 지균풍이 된다. 그러나 실제 대기에서는 이상적인 조건이 정확히 성립하는 경우는 거의 없으며, 바람구조는 매우 민감하기 때문에, 완벽한 에크만 나선은 일반적으로 존재하지 않는다.
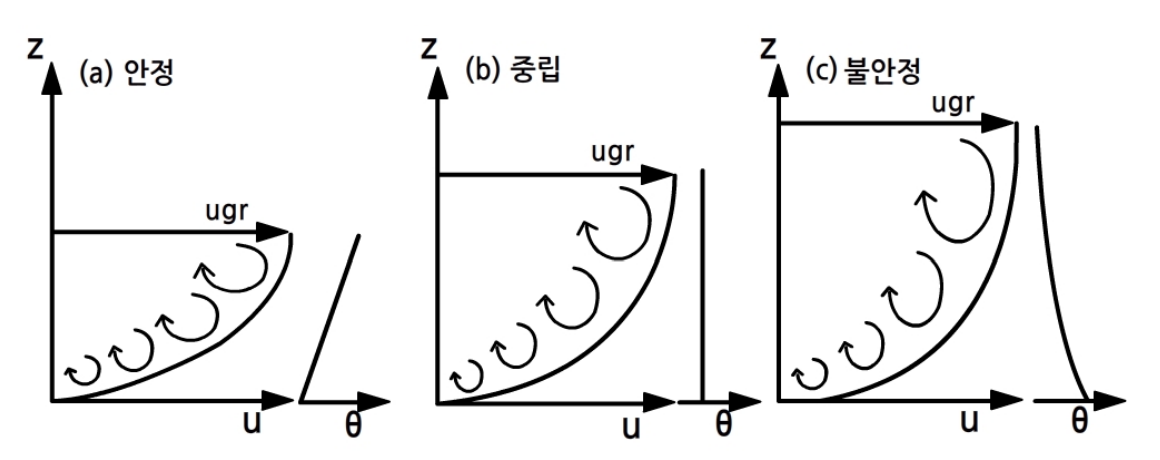
대기가 불안정하다면, 연직 운동의 확장 때문에 난류의 연직 발달은 강화된다. 반면에 안정한 상태에서의 난류의 연직 발달은 약화된다. 에디(소용돌이 Vortex)들은 중립 경계층에서 w' = u'로 회전한다. 불안정한 경계층에서의 역학적 난류는 여전히 지표 부근에서는 지배적이나, 고도가 증가함에 따라 부력의 영향에 의해 w' > u'의상태가 되기 때문에, 에디는 연직으로 뻗어 나간다. 그러므로 위로부터의 운동량 플럭스는 강화되고, 저층에서의 바람은 강해진다.
그림 9. 안정도에 따른 에디 형태와 바람과 온위의 프로파일
안정한 경계층일 경우, 지표 부근에서는 역학적 난류가 지배적이고 에디는 회전하나, 고도가 증가함에 따라 부력이 연직 운동에 저항하여 버팀으로서 에디는 옆으로 평평하게 펴지는 형태가 된다. 즉, 의 상태가 되고, 위로부터의 운동량 플럭스가 억제되기 때문에 지표 부근의 바람은 약해진다(그림 9).
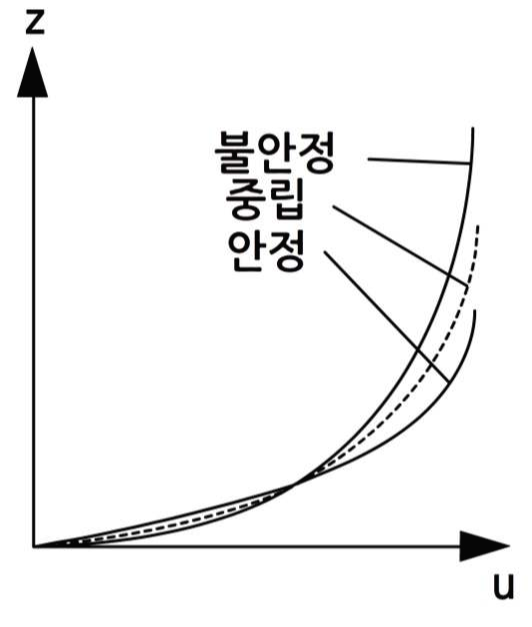
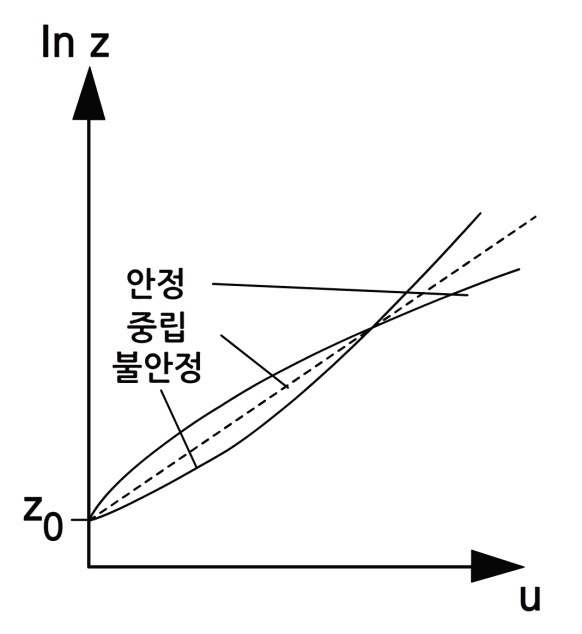
이러한 안정한 상태에서 억제된 운동량 플럭스는 비록 중립의 경우보다 지표 부근의 바람이 더 약하다 할지라도 하층에서의 운동량 손실이 없는 만큼 고도별 바람은 더 강하다는 것을 의미한다. 불안정한 상태에서 운동량은 경계층 내에서 더 균등하게 분산된다. 그 결과, 고도별 바람은 중립의 경우 보다 더 약하고, 지표 부근의 바람은 더 강하다. 이러한 연직 변화량의 증가는 경계층을 더 깊게 하고, 반면에 안정한 프로파일은 경계층 깊이를 제한 한다(그림 10, 그림 11).
그림 10. 그림 9의 윈드 프로파일들을 합친 경우 (출처: Met Office)
그림 11. 그림 10의 로그 프로파일 형태 (출처: Met Office)
이론적 대수법칙 프로파일로 부터의 이러한 시도들은 식 (11.14)가 단지 중립 상태의 경계층 깊이 전체에 걸쳐서 유효하다는 것을 의미한다. 또한, 역학적 힘이 부력보다 지배적이고, 에디들이 회전하는 몇 미터 안 되는 최 하층에서는 여전히 유효하다.
역학적 vs. 부력 메커니즘 (Mechanical vs. Buoyancy mechanisms)
비중립 상태일 경우, 경계층에서의 난류 발생에 있어서 역학적 메커니즘 대 부력 메커니즘의 상대적 중요성은 Monin-obukhov 안정도 길이(L), 시어(shear) 대 부력의 비율로 나타내어진다.
고도 z를 고려하면, z < L 의 경우는 시어가 난류 형성에 지배적이고, 반면에 z > L 의 경우는 부력이 지배적이다.
전형적으로, 대류가 활발한 주간에는 이 약 50m이고, 그 아래에서는 시어가 지배적이다. 매우 안정적인 야간에는 이 약 10m이다.
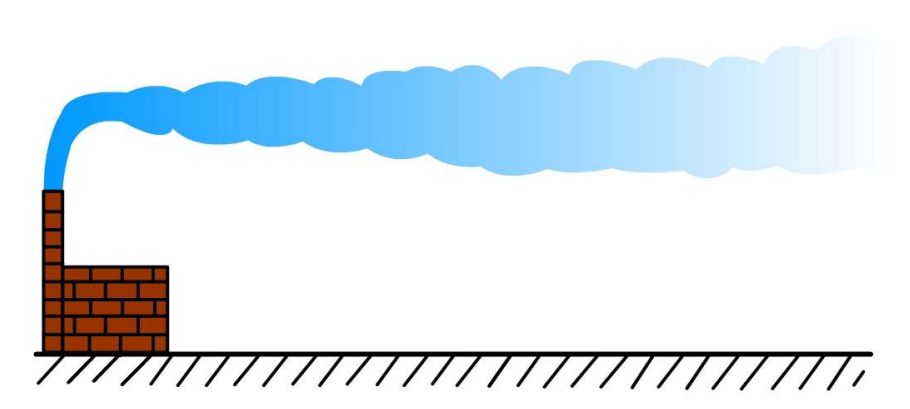
굴뚝 배출 연기 형태 (Smoke plumes)
1. 중립상태
중립 상태의 유리한 조건은 강한 바람과 흐린 하늘이다. 그러한 상황에서, 지표는 열 에너지원으로 작용하지 않고, 공기는 가열되지 않는다. 기온감율 은 단열감율이고, 연직 변위하는 공기 덩어리에 부력이 작용하지 않는다. 그러므로 이러한 중립상태에서의 굴뚝에서 배출되는 연기는 같은 수평과 연직 비율로 순풍 방향으로 퍼져 나가며, 그림 12와 같은 원추형 (Coning)을 나타낸다.
그림 12. 중립상태에서의 원추형(coning) 굴뚝 연기
2. 불안정 상태
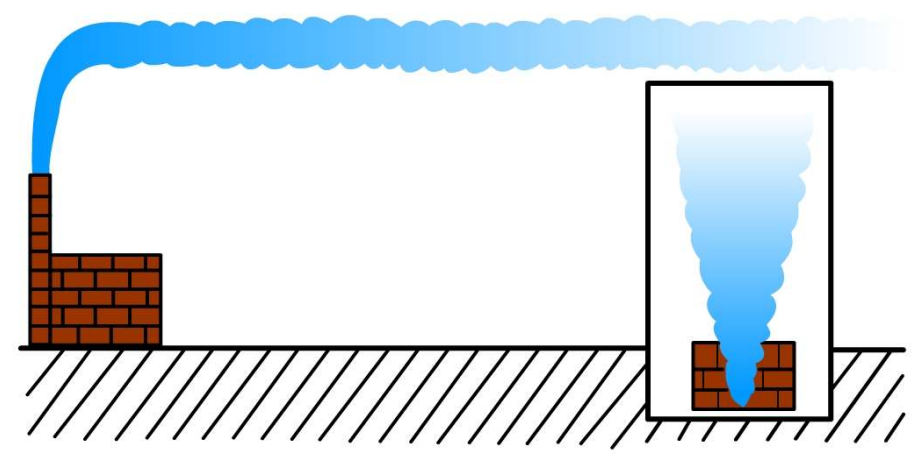
불안정한 경계층은 약한 바람과 햇빛이 있는 주간에 전형적으로 나타난다. 지표는 데워지고, 그 열은 하층 대기로 이동한다. 이것은 온도 상승과 자유 대류혼합을 일으키고, 불안정한 기온감율을 야기한다. 또한, 따뜻한 바다위 에서 부는 차가운 공기도 불안정한 경계층을 발생시킨다. 이 두 경우에, 강 한 바람이 불면 역학적 난류가 증가되고 연직교환을 위한 자유 대류가 덜 지배적이기 때문에 경계층이 중립적으로 되어 간다. 매우 불안정한 대기에 서, 굴뚝에서 배출되는 연기 형태는 그림 13과 같은 큰 대류성 에디들에 대응하는 환상형(Looping) 패턴을 보인다.
그림 13. 불안정 상태에서의 환상형 (looping) 굴뚝 연기
3. 고요한 상태
고요한(Calm) 야간의 육상에서 발달하는 경계층은 안정 상태이다. 지표면 은 열을 손실하고, 대기 최하층부는 차가워진다. 이로 인하여 역학적인 난 류를 억제하는 안정적인 기온감율이 나타난다. 이러한 안정적인 상태에서 적당히 거칠은 지표일 경우의 10m 바람은 일반적으로 경도풍(Gradient Wind)의 25%정도 이고, 중립 상태에서는 50%, 불안정 상태에서는 70%정
도 이다. 또한, 불안정 경계층의 경우에 언급했듯이, 바람 강도의 증가는 경 계층을 더 중립적으로 만든다. 이때, 혼합에 의하여 차가운 공기는 위로 보 내지고, 위에 있던 따뜻한 공기는 아래로 내려온다. 대기가 안정한 상태일 때, 굴뚝에서 배출되는 연기는 순풍 방향으로 수평하게 퍼져 나가지만, 연 직으로는 퍼지지 않는다. 그러므로 연기형태는 그림 14와 같이 부채형 이다.
그림 14. 안정 상태에서의 부채형(fanning) 굴뚝 연기. 삽입된 그림은 원추형과 부채형을 위에서 봤을 때 옆으로 퍼지는 형태를 나타냄.