분류 전체보기
- 가중치 Weights를 출력하는 방법 2022.01.20
- ValueError: Input 0 of layer "sequential" is incompatible with the layer: expected shape=(None, 100, 1), found shape=(None, 21) 2022.01.20
- Importance 바차트 출력 2022.01.17
- GridSearchCV 평가 - 최적 파라미터 출력 2022.01.17
- def roc_curve_plot() 함수 코드 2022.01.17
- def get_clf_eval() 함수 코드 2022.01.17
- 시계열 데이터 - 슬라이더로 살펴보기 2022.01.14
- 라디오존데 - 플라스틱 쓰레기 2022.01.14
- 모델 저장 및 불러오기 2022.01.11
- AttributeError: Can only use .dt accessor with datetimelike values 2022.01.07
- 수증기압 포차 (vapor pressure deficit, VPD) 2021.12.30
- 대학 들어 왔으면 수익 내야지 왜 남 좋은 일 시키니? 2021.12.30
- graphviz 사용법 (링크) 2021.12.28
- Jupyter notebook 시작 디렉토리 설정이 안된다면... 2021.12.27
- graphviz 간단 설치 방법 (윈도우10) 2021.12.27
- graphviz 초간단 설치 (윈도우10) 2021.12.27
- pip install 과 conda install 의 차이점 2021.12.27
- XGBoost 초간단 설치(윈도우10) 2021.12.27
- 분류 - 개요 2021.12.27
- 지구는 우리가 아는 한 유일하게 '생물권'을 가진 행성이다. 2021.12.27
가중치 Weights를 출력하는 방법
2022. 1. 20. 14:59
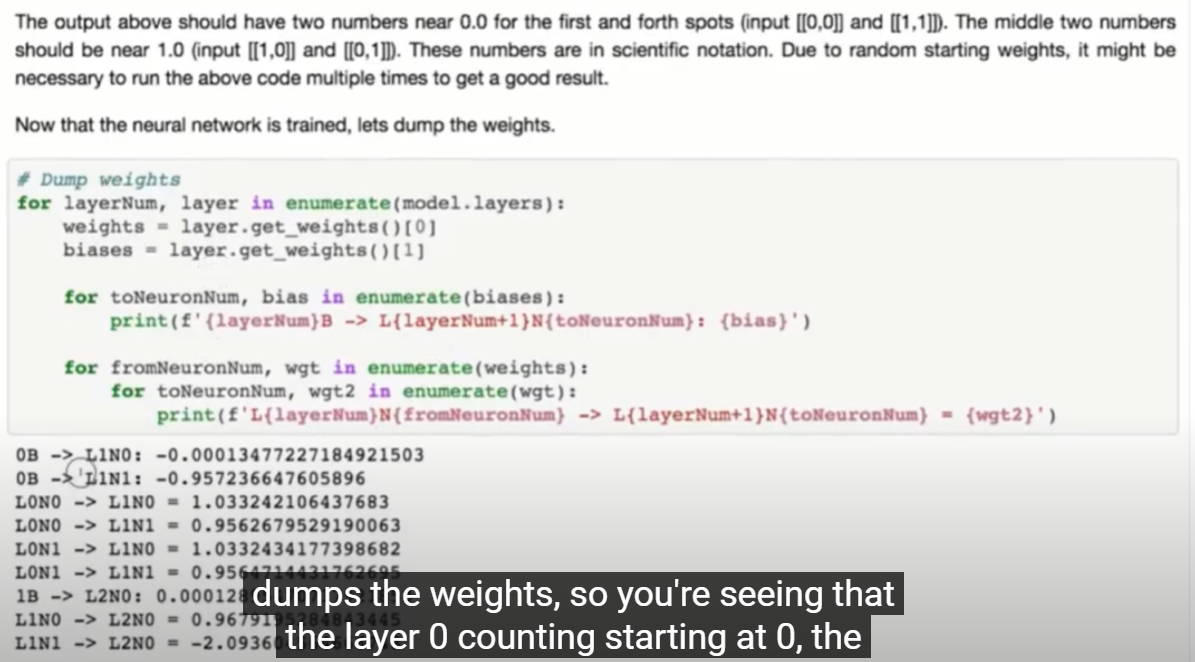

ValueError: Input 0 of layer "sequential" is incompatible with the layer: expected shape=(None, 100, 1), found shape=(None, 21)
2022. 1. 20. 11:54
728x90
반응형
LSTM 다룰 때 중요한 부분!
에러
ValueError: Input 0 of layer "sequential" is incompatible with the layer: expected shape=(None, 100, 1), found shape=(None, 21)
원인
LSTM 모델을 사용할 때는, train 차원을 바꾸어야 하는데, 차원 변경을 해 주지 않으면 발생하는 에러
해결
X_train = X_train.reshape(X_train.shape[0], X_train[1], 1)
명령으로 2차원 데이터를 3차원으로 변경하면 됨.
728x90
반응형
Importance 바차트 출력
2022. 1. 17. 17:59
728x90
반응형
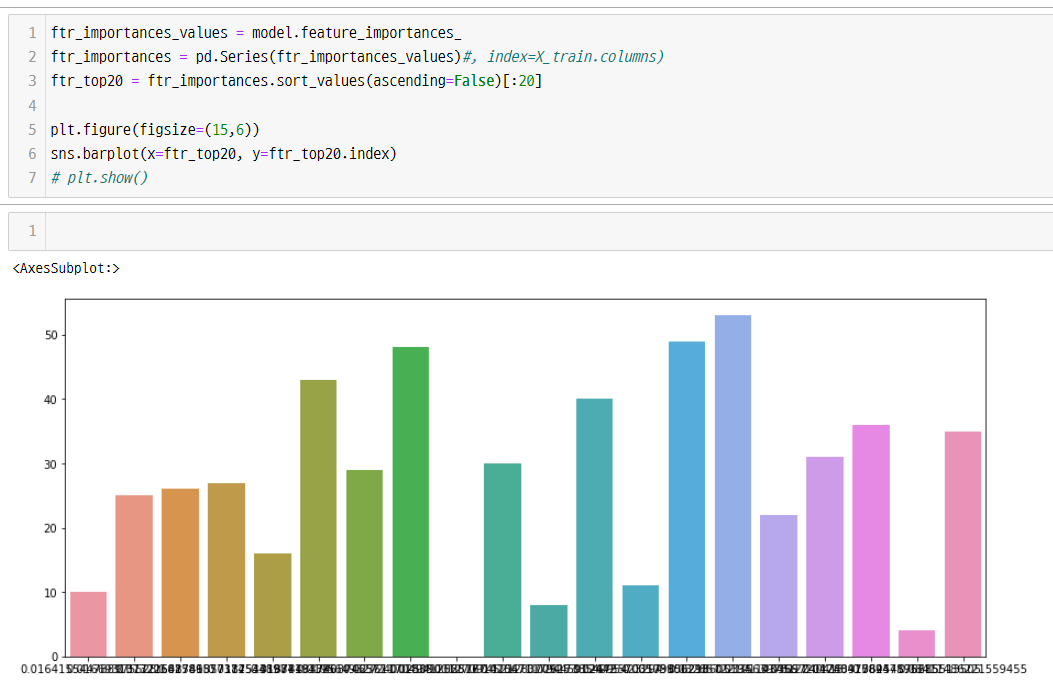
코드
ftr_importances_values = model.feature_importances_
ftr_importances = pd.Series(ftr_importances_values)#, index=X_train.columns)
ftr_top20 = ftr_importances.sort_values(ascending=False)[:20]
plt.figure(figsize=(15,6))
sns.barplot(x=ftr_top20, y=ftr_top20.index)
# plt.show()
728x90
반응형
GridSearchCV 평가 - 최적 파라미터 출력
2022. 1. 17. 17:49
728x90
반응형


코드
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators':[100],
'max_depth' : [6,8,10.,12],
'min_samples_leaf' : [8,12, 18],
'min_samples_split' : [8,16, 20]
}
rf_clf = RandomForestClassifier(random_state=0)
model = rf_clf
grid_cv = GridSearchCV(model, param_grid=params, cv=2, n_jobs=-1)
grid_cv.fit(X_train, y_train)
print('Best parameter:\n', grid_cv.best_params_)
print('Highest accuracy: {0:.4f}'.format(grid_cv.best_score_))
출처: 파이썬 머신러닝 완벽가이드 p220
728x90
반응형
def roc_curve_plot() 함수 코드
2022. 1. 17. 17:19
728x90
반응형
def roc_curve_plot(y_test, pred_proba_c1):
fprs, tprs, thresholds = roc_curve(y_test, pred_proba_c1)
plt.plot(fprs, tprs, label='ROC')
plt.plot([0,1], [0,1], 'k--', label='Random')
start, end = plt.xlim()
plt.xticks(np.round(np.arange(start, end, 0.1), 2))
plt.xlim(0,1);plt.ylim(0,1)
plt.xlabel('FPR( 1 - sensitivity )'); plt.ylabel('TPR( Recall )')
plt.legend()
728x90
반응형
def get_clf_eval() 함수 코드
2022. 1. 17. 16:21
728x90
반응형
from sklearn.metrics import accuracy_score, precision_score, recall_score, confusion_matrix, f1_score, roc_auc_score
from sklearn.metrics import roc_curve
def get_clf_eval(y_test, pred=None, pred_proba=None):
confusion = confusion_matrix(y_test, pred)
accuracy= accuracy_socre(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
f1 = f1_score(y_test, pred)
roc_auc = roc_auc_score(y_test, pred_proba)
print('error matrix')
print(confusion)
print('Accu : {0:.4f}, Prec : {1:.4f}, Recu : {2:.4f},\
F1 : {3:.4f}, AUC : {4:.4f}'.format(accuracy, precision, recall, f1, roc_auc))728x90
반응형
시계열 데이터 - 슬라이더로 살펴보기
2022. 1. 14. 16:07
728x90
반응형
전처리 과정에서, 시계열 데이터를 살펴볼때 아래와 같이 slider 를 사용하면 missing-data 를 찾거나, 경향성 파악에 크게 도움이 된다.
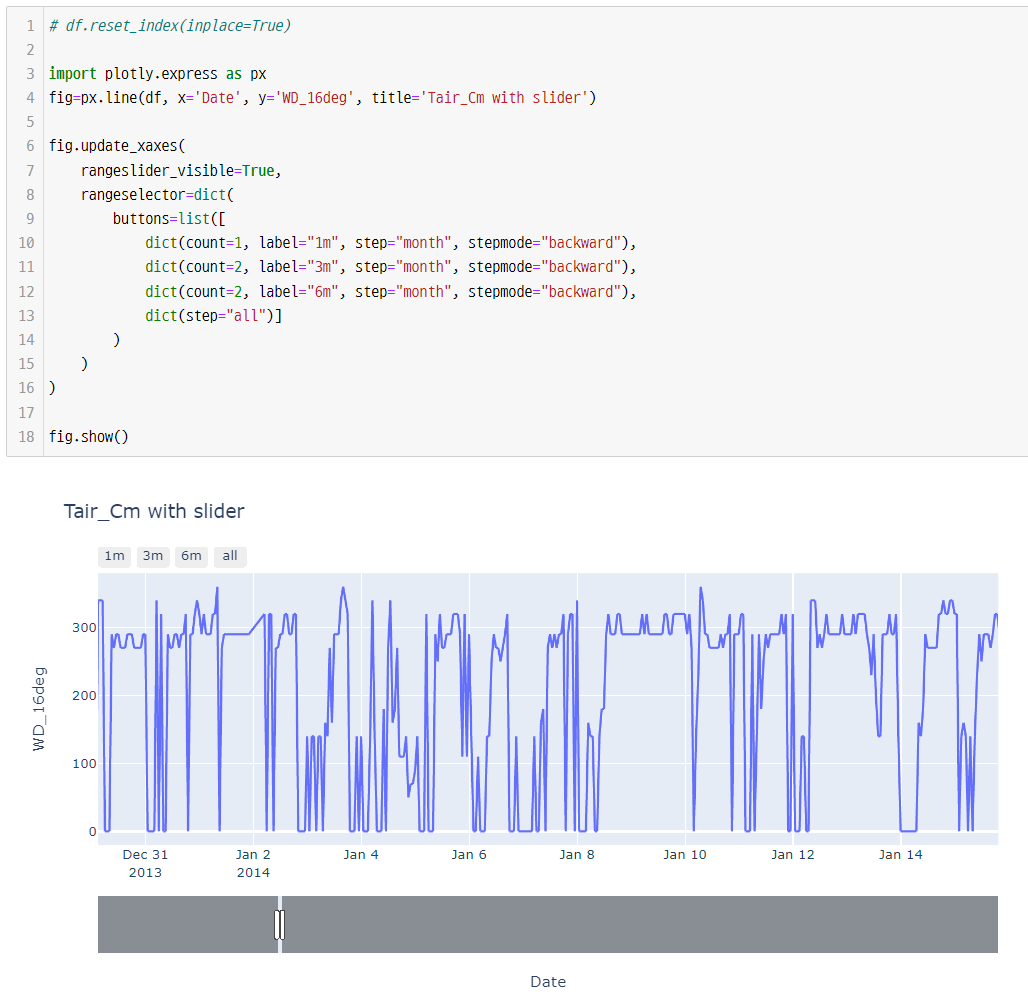
코드
df.reset_index(inplace=True)
import plotly.express as px
fig=px.line(df, x='Date', y='Tair_C', title='Tair_Cm with slider')
fig.update_xaxes(
rangeslider_visible=True,
rangeselector=dict(
buttons=list([
dict(count=1, label="1m", step="month", stepmode="backward"),
dict(count=2, label="3m", step="month", stepmode="backward"),
dict(count=2, label="6m", step="month", stepmode="backward"),
dict(step="all")]
)
)
)
fig.show()
728x90
반응형
라디오존데 - 플라스틱 쓰레기
2022. 1. 14. 12:06
728x90
반응형
연직 고층 기상 관측장비인 라디오존데가 플라스틱 쓰레기 논란에 휘말렸다.
아무리 위성관측과 원격측정 기술이 발전해도 대기 구조를 직접관측하는 유일한 장비인 라디오존데.
기온이 영하인 고층에서의 방온유지를 위해 스티로폼을 포장재로 사용할 수 밖에 없고, 각 종 센서와 기기판등이 지상으로 낙하되면 쓰레기로 처리될 수 밖에 없다.
요즘은 바람까지 측정가능한 GPS 기능이 탑재된 레윈존데가 사용된다.
예전에는 주소라도 써서 기상청에서 수거하는 경우가 간혹있었지만, 지금은 바다에 낙하하면 수거 불가능.
전세계에서 연간 1억개의 라디오존데를 띄우고, 약 10억 이상의 예산이 쓰인다.
매년 85만개 하늘의 플라스틱 쓰레기 라디오존데 (ecoday.kr)
매년 85만개 하늘의 플라스틱 쓰레기 라디오존데
39억 투입 ′친환경라디오존데′ 만들고도 무용지물전혀 활용하지 못한 채 폐기한 기상청 현실 드러나 2013~15년까지 단 한 차례도 활용 못한 채 폐기세계적 기상장비 업체 Vaisala사 ′반환경 부정
ecoday.kr
728x90
반응형
모델 저장 및 불러오기
2022. 1. 11. 13:30
728x90
반응형
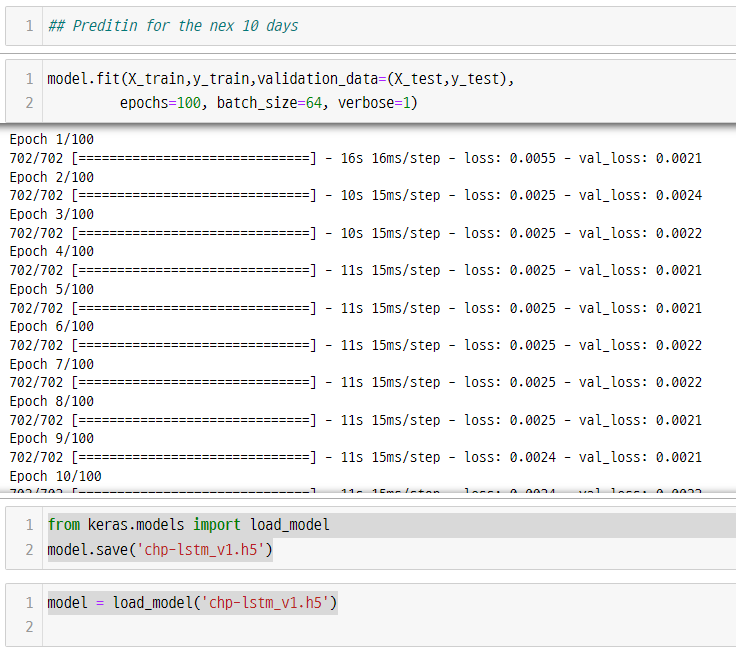
728x90
반응형
AttributeError: Can only use .dt accessor with datetimelike values
2022. 1. 7. 14:03
728x90
반응형
datetime 변환 코드 상에서 이와 같은 에러가 발생
pandas 데이터 인식이 잘 못된 경우일 수 있다. 아래와 같이 설정
train["datetime"] = pd.to_datetime(train["datetime"])
.dt에서 어트리뷰트 에러발생 - 인프런 | 질문 & 답변 (inflearn.com)
.dt에서 어트리뷰트 에러발생 - 인프런 | 질문 & 답변
train['year'] = train['datetime'].dt.year train['month'] = train['datetime'].dt.month train['day'] = train['datetime'].dt.day train['hour'] = train['...
www.inflearn.com
728x90
반응형
수증기압 포차 (vapor pressure deficit, VPD)
2021. 12. 30. 15:32
728x90
반응형
Vapor Pressure Deficit(VPD) Guide (tistory.com)
Vapor Pressure Deficit(VPD) Guide
VPD를 이용하면 식물이 성장하는데 필요한 정확한 온도 및 습도 범위를 식별 할 수 있다. VPD를 이용하면 해충 및 환경 문제를 피하면서 최상의 결과를 얻을 수 있다. VPD는 식물의 증산 속도, 기공
makerjeju.tistory.com
VPD(수증기 압차:Vapour-pressure deficit) 계산 : 네이버 블로그 (naver.com)
VPD(수증기 압차:Vapour-pressure deficit) 계산
온도, 습도값에 따른 VPD과 작물 증산 - 녹색구간이 작물 생육에 좋은 증산 구간 VPD과 증산 1. 압력...
blog.naver.com
728x90
반응형
대학 들어 왔으면 수익 내야지 왜 남 좋은 일 시키니?
2021. 12. 30. 00:00
graphviz 사용법 (링크)
2021. 12. 28. 16:34
Jupyter notebook 시작 디렉토리 설정이 안된다면...
2021. 12. 27. 16:40
728x90
반응형
인터넷 검색을 해 보면,
{사용자}\ .jupyter 폴더 내 jupyter_notebook_config.py 파일의
#c.NotebookApp.notebook_dir = '' 부분에
코멘트(#)을 제거하고, 원하는 폴더 경로를 적으라고 되어있는데,
그래도 안된다!!!
그래서, 초단간 방법을 소개한다.
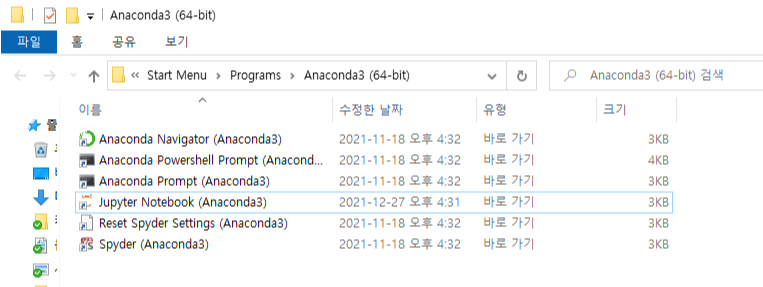
1. 아래와 같이 Jupyter Notebook 바로가기에서 오른쪽 클릭
2. 바로가기> 대상(T)와 시작위치(S)에 자신이 원하는 시작 폴더 경로를 넣어 주면 된다.
이때, 쌍따옴표에 유의한다.
3. Jupyter notebook 재 실행 하면, 시작 폴더가 변경된 것을 확인할 수 있다.

728x90
반응형
graphviz 간단 설치 방법 (윈도우10)
2021. 12. 27. 16:33
728x90
반응형
1. 아래 사이트에서 윈도우용 graphviz 를 다운받는다. 안정화 버전을 추천함.
https://graphviz.org/download/
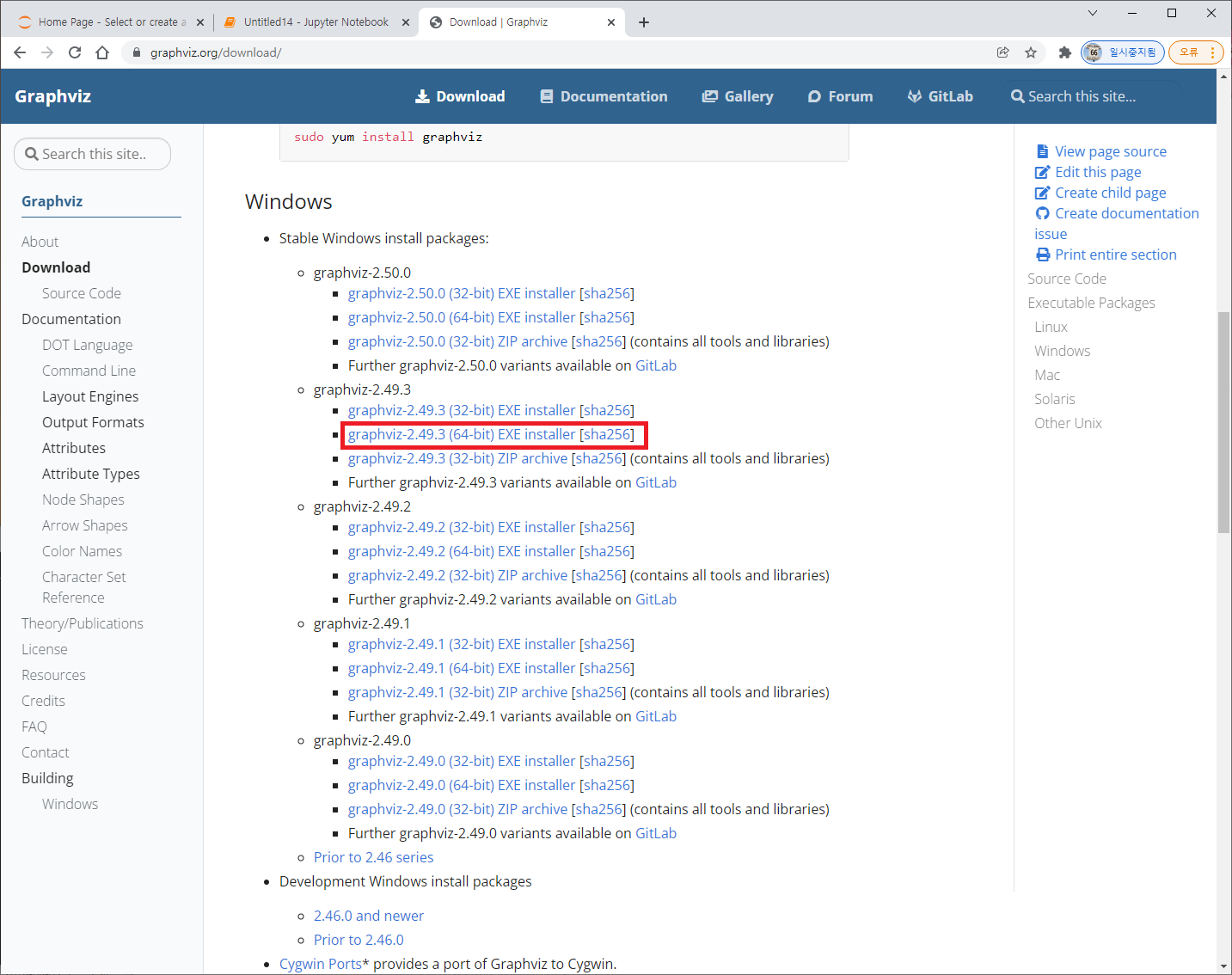
2. 설치한다.
3. Anaconda 콘솔을 관리자 권한으로 실행하고, 아래 명령어 실행
>>> pip install grpahviz
4. 윈도우 환경변수에서 사용자 변수와 시스템 변수를 각각 아래와 같이 수정한다.
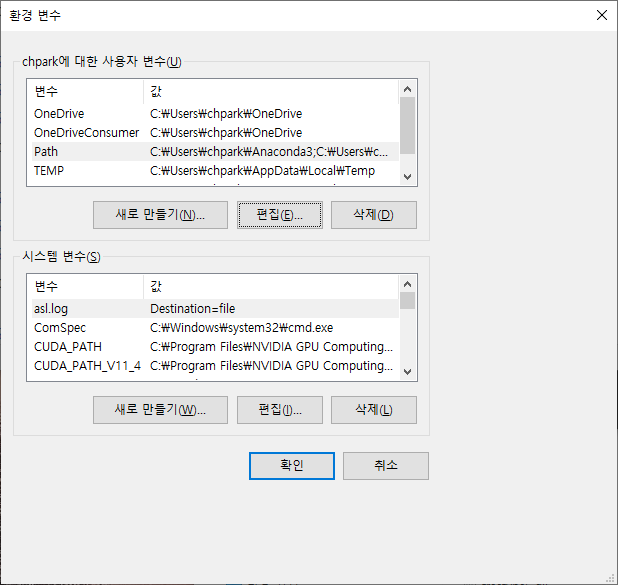
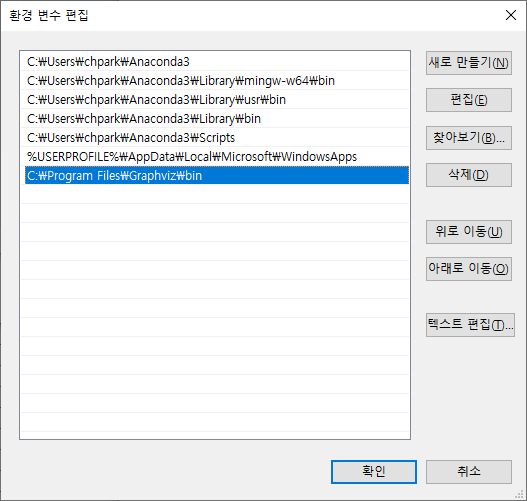
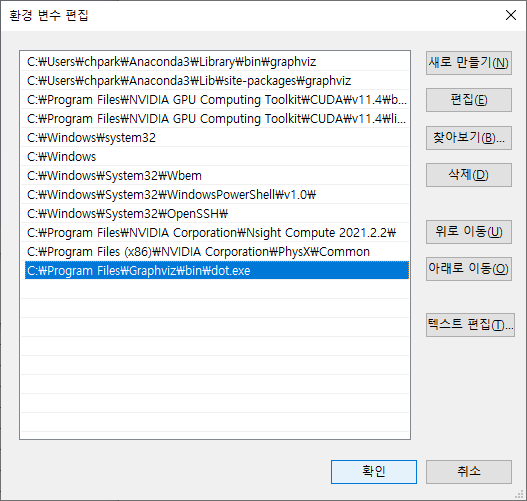
5. Jupyter notebook을 모두 재부팅
6. 아래 명령어 실행하여 확인

728x90
반응형
graphviz 초간단 설치 (윈도우10)
2021. 12. 27. 16:11
728x90
반응형
1. 아래 사이트에서 윈도우용 graphviz 를 다운받는다. 안정화 버전을 추천함.
https://graphviz.org/download/

2. 설치한다.
3. Anaconda 콘솔을 관리자 권한으로 실행하고, 아래 명령어 실행
>>> pip install grpahviz
4. 윈도우 환경변수에서 사용자 변수와 시스템 변수를 각각 아래와 같이 수정한다.
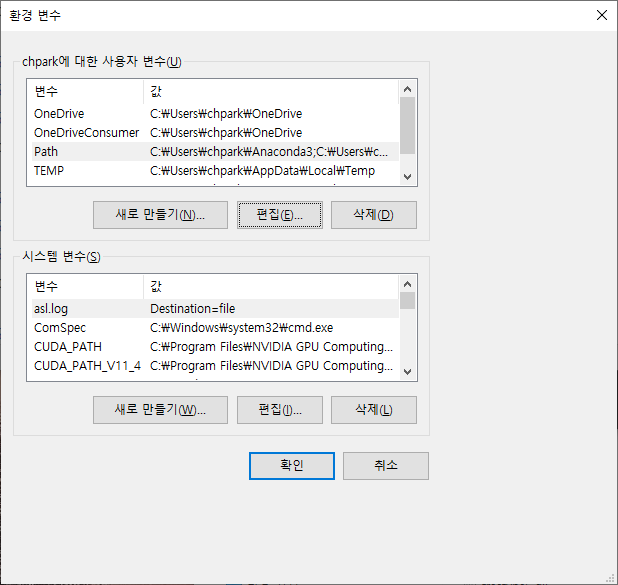
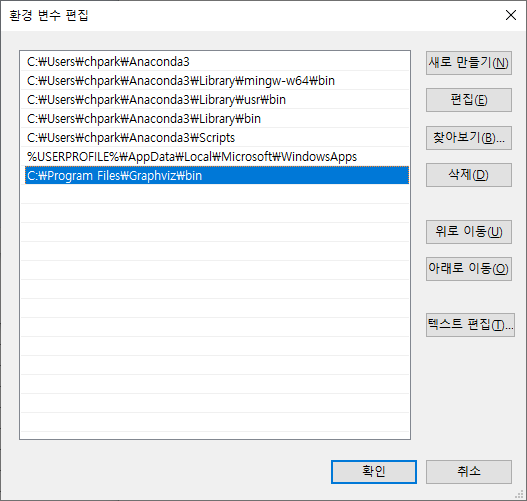
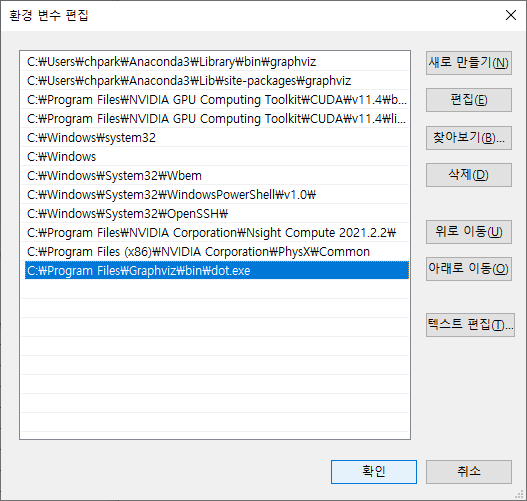
5. Jupyter notebook을 모두 재부팅
6. 아래 명령어 실행하여 확인

728x90
반응형
pip install 과 conda install 의 차이점
2021. 12. 27. 15:37
728x90
반응형
conda install graphviz 를 쳐서 설치를 하자
찾아보니 conda install로 설치를 하면
C:\Users\Anaconda3\Library\bin\graphviz
이 위치에 설치된다.
그런데 pip install로 하면 아래 경로에 설치가 된다.
C:\Users\Anaconda3\Lib\site-packages\graphviz
[출처] [파이썬][머신러닝] graphviz 설치/실행 에러 해결하기|작성자 하쿠나마타타
728x90
반응형
XGBoost 초간단 설치(윈도우10)
2021. 12. 27. 12:13
728x90
반응형
아래와 같이 복잡하게 하지 말고, 그냥
(base) pip install xgboost
하면 된다.
conda install 을 사용하면, 아래와 같이 python 버전에 따라 PakcagesNotFoundError 가 발생한다.
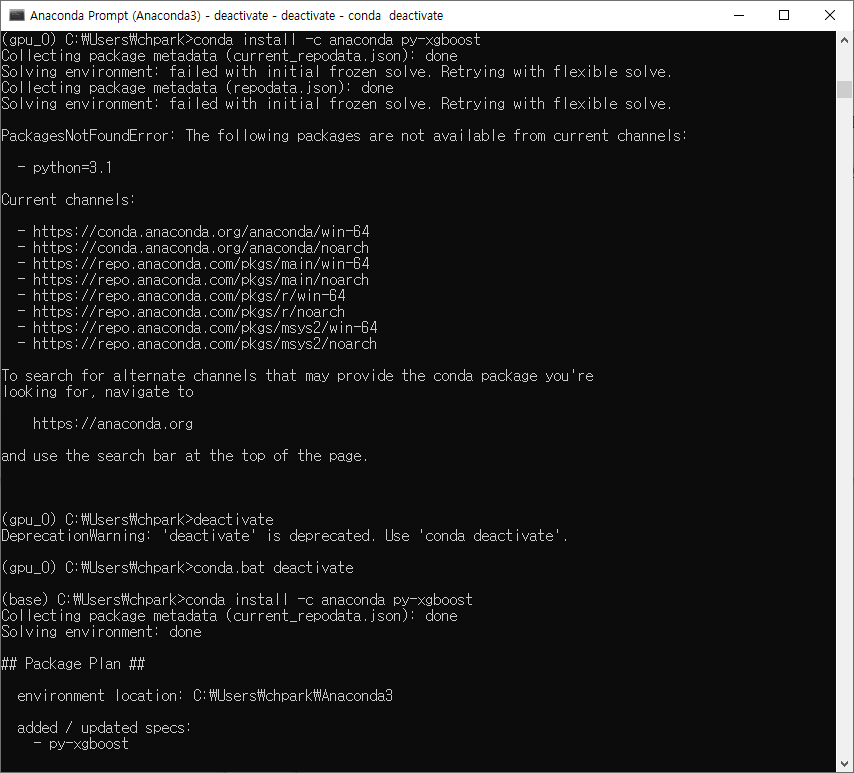
XGBOOST 설치방법
1) https://www.lfd.uci.edu/~gohlke/pythonlibs/#xgboost
2) 현재 pyton 3.10 설치된 상태이므로, xgboost-1.5.1-cp310-cp310-win_amd64.whl 다운 받는다.
3) 다운로드한 파일을 C:\Users\chpark\Anaconda3\pkgs\python-3.10.0-h96c0403_3\Lib\site-packages 에 저장
4) 다운 받은 폴더에 가서, pip install xgboost-1.5.1-cp310-cp310-win_amd64.whl
5) Jupyter notebook 에서 아래 명령어가 에러 나지 않으면 설치된 것임.
import xgboost as xgb

728x90
반응형
분류 - 개요
2021. 12. 27. 11:11
728x90
반응형
앙상블 방법
분류에서 가장 각광 받는 방법
이미지, 영상, 음성,NLP 영역에서 신경망ㅌㅊ에 기반한 딥러닝이 머신러닝계를 선도하고 있지만, 이를 제외한 정형 데이터의 예측 분석 영역에서는 앙상블ㅇ리 매우 높은 예측 성능으로 애용되고 있음.
앗으븡:
서로 다른/또는 같은 알고리즘을 단순히 결하한 형태이나, 일반적으로 배팅과 부스팅 방식으로 나눔.
배깅방식: 랜덤 포레스트 - 뛰어나난 예측 선응 상대적으로 빠른 수행 시간, 유연성
최근에는 부스팅 방식으로 발전하고 있음. 그래디언트 부스팅(효쇠) 뛰어난 예측 성능이지만, 시간이 너무 오래 걸림따라서 최적화 모델 튜닝이 어려움
XgBoost , lightGBM 등 기존 그래디언트 부스팅의 예측 성능을 한단계 발전시키ㅁ녀서 수행시간을 단축시킨 알고리즘
정형 데이터 분류 영여ㅓㄱ에서 가장 활용도가 높으 ㄴ알고리즘으로 자리 잡음
랜덤 포레스트
그래디언트 부스닝
XGboost LightGMBM 스태킹 기법에 대해ㅓㅅ 살료봄.
앙상블의 기본 알고리즘 --> 결정트리
결정트리: 쉽고 유연
스케일링이나 정규화 등의 영향이 적다.
복잡한 구조로 인한 과적합이 발생하여 예측 성능이 저하될 수도 있음.
하지마나 이것이 오ㄹ히려 장점
왜냐하면, 앙상블은 매우 많은 여러개의 약한 학습기(예측 성능이 상대적으로 낮은 학습 알고리즘)를 결합해 확률적 보와노가 유로가 발생한 부분에 대한 가중치를 계속 업데티으하면서 옟윽 성능을 향상시키는데 결정 트리가 좋은 약한 학습기가다 되기때문
결정트리
앙상블 학습
랜덤 포레스트
GBM
XGBoost
LightGBM
캐글 산탄데르 고객 만족 예측
출처: 파이썬 머신러닝 완벽가이드
728x90
반응형
지구는 우리가 아는 한 유일하게 '생물권'을 가진 행성이다.
2021. 12. 27. 08:54
728x90
반응형

728x90
반응형