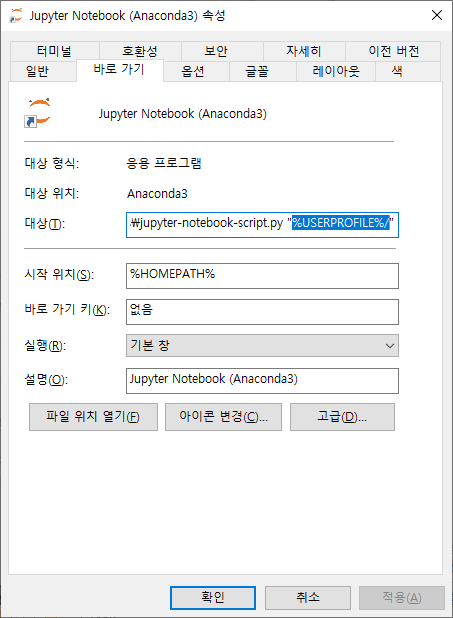
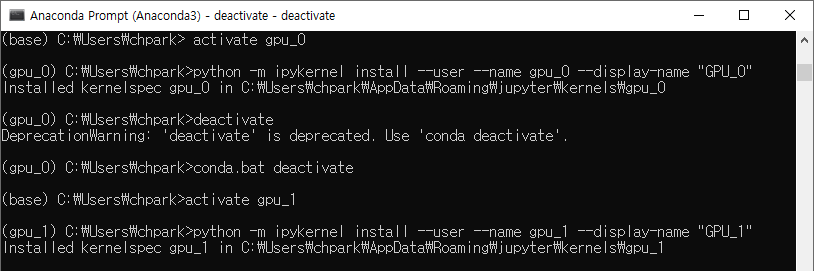
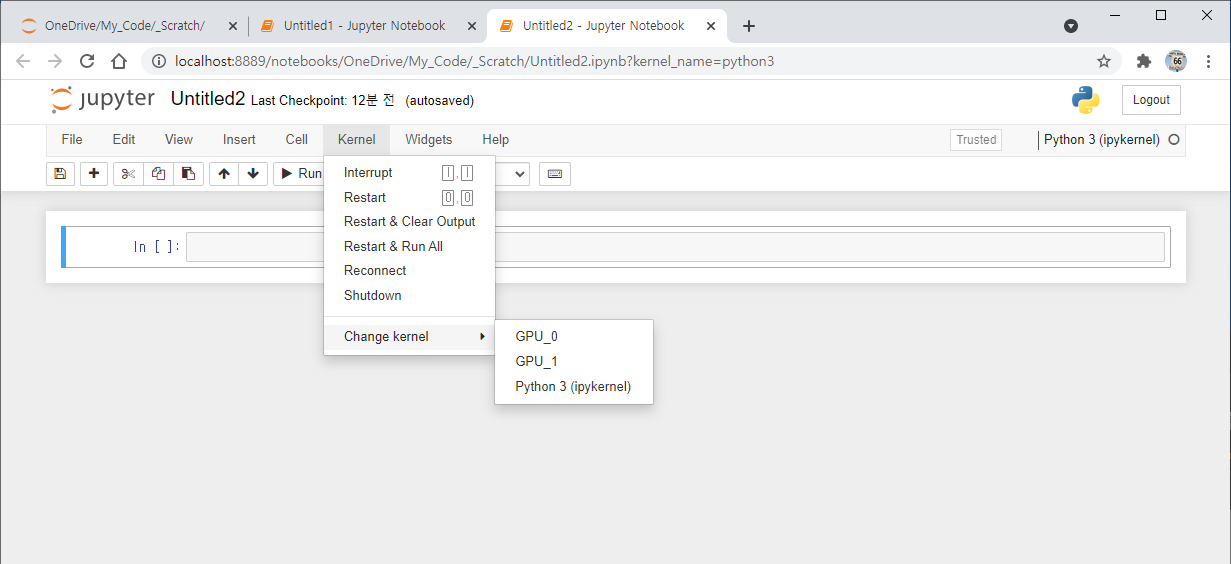
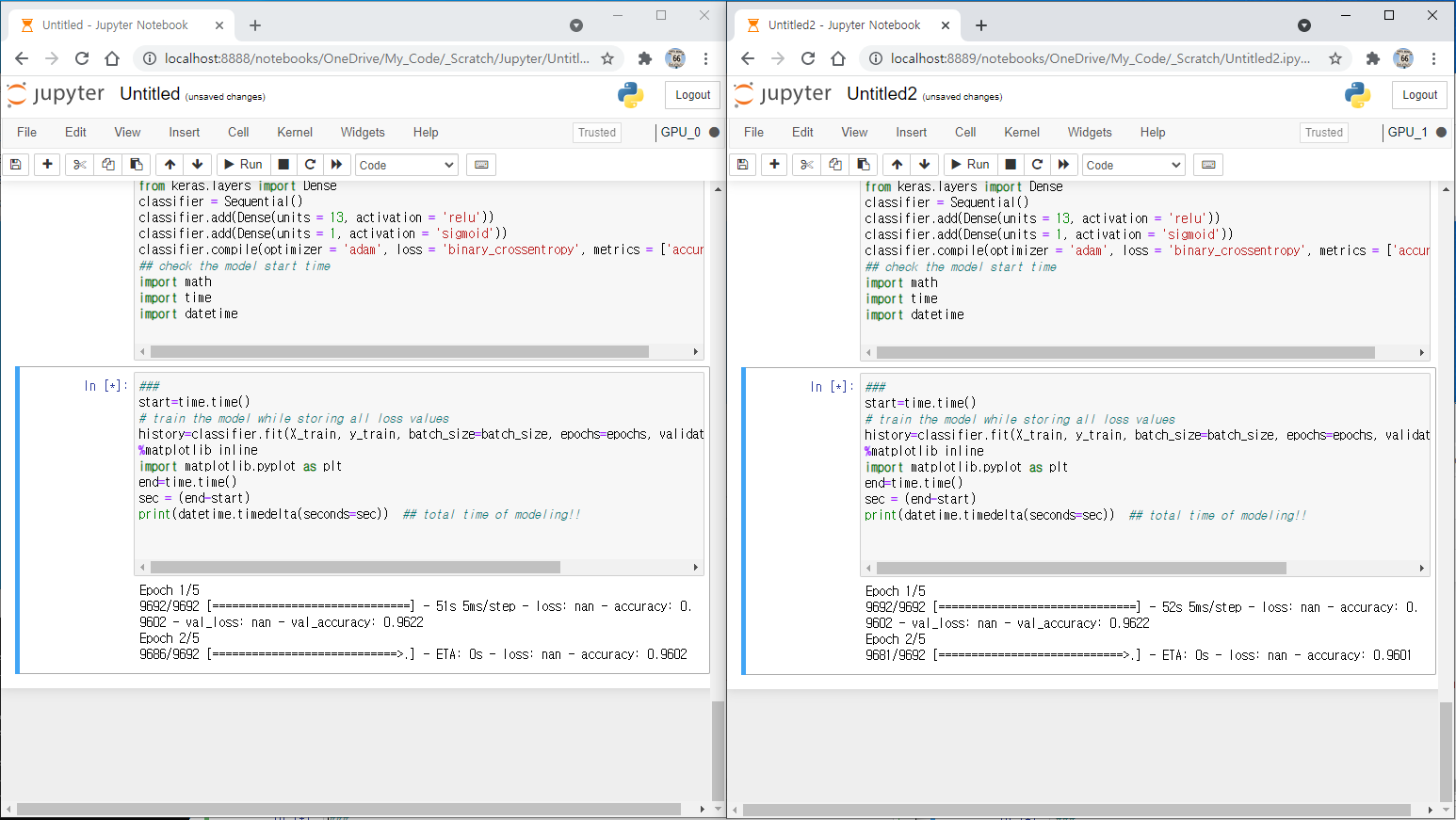
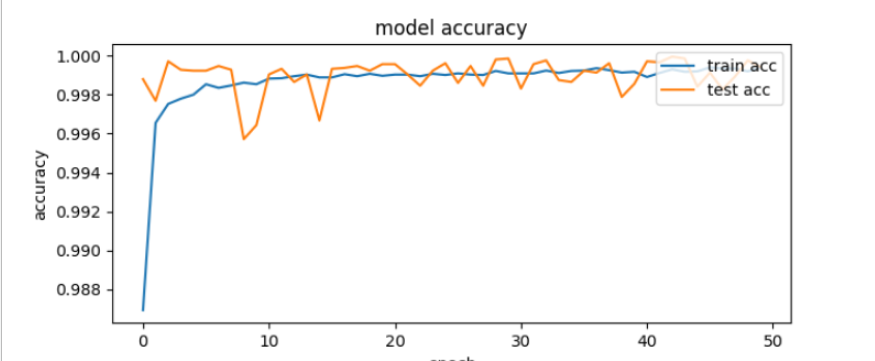
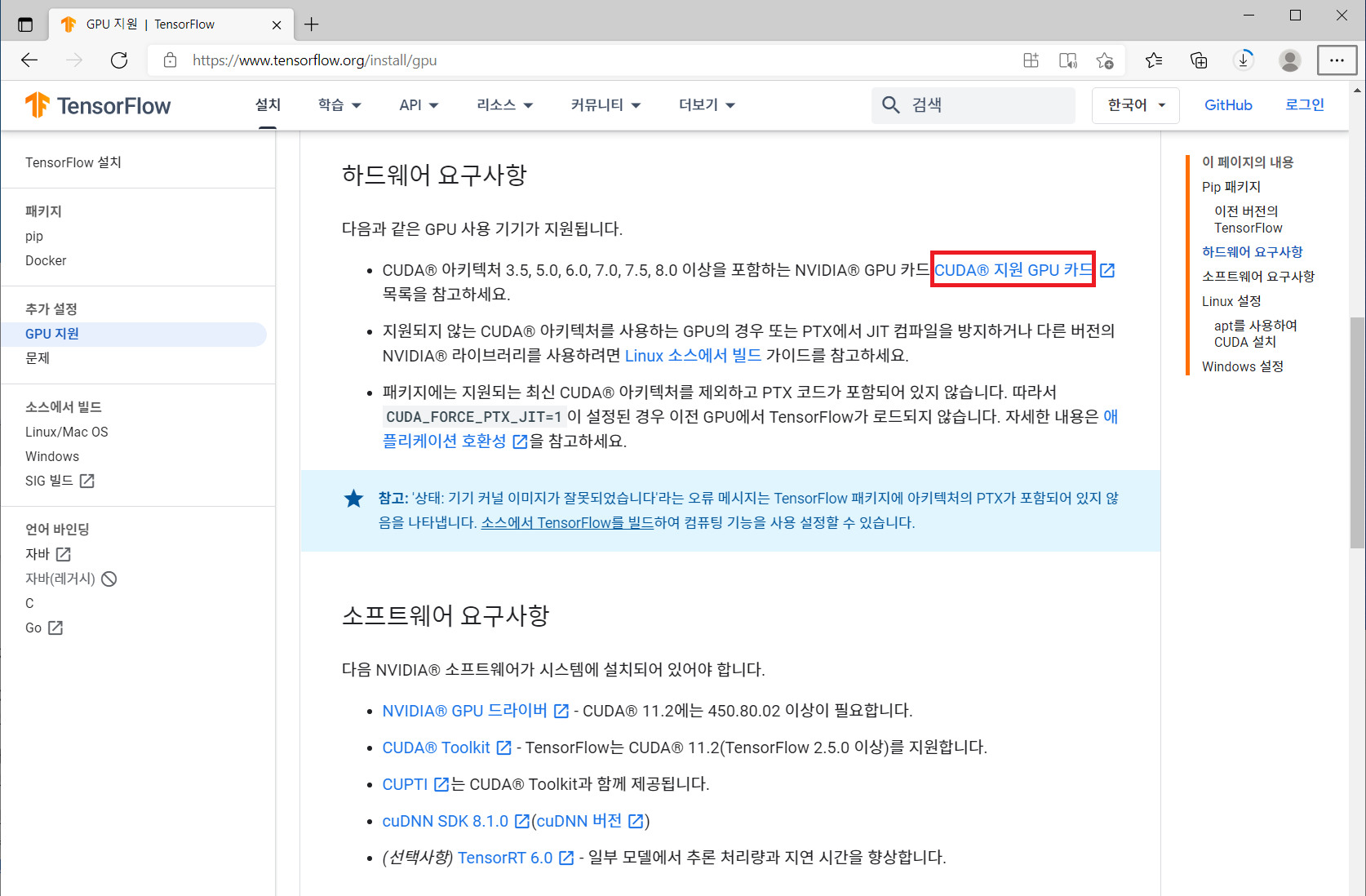
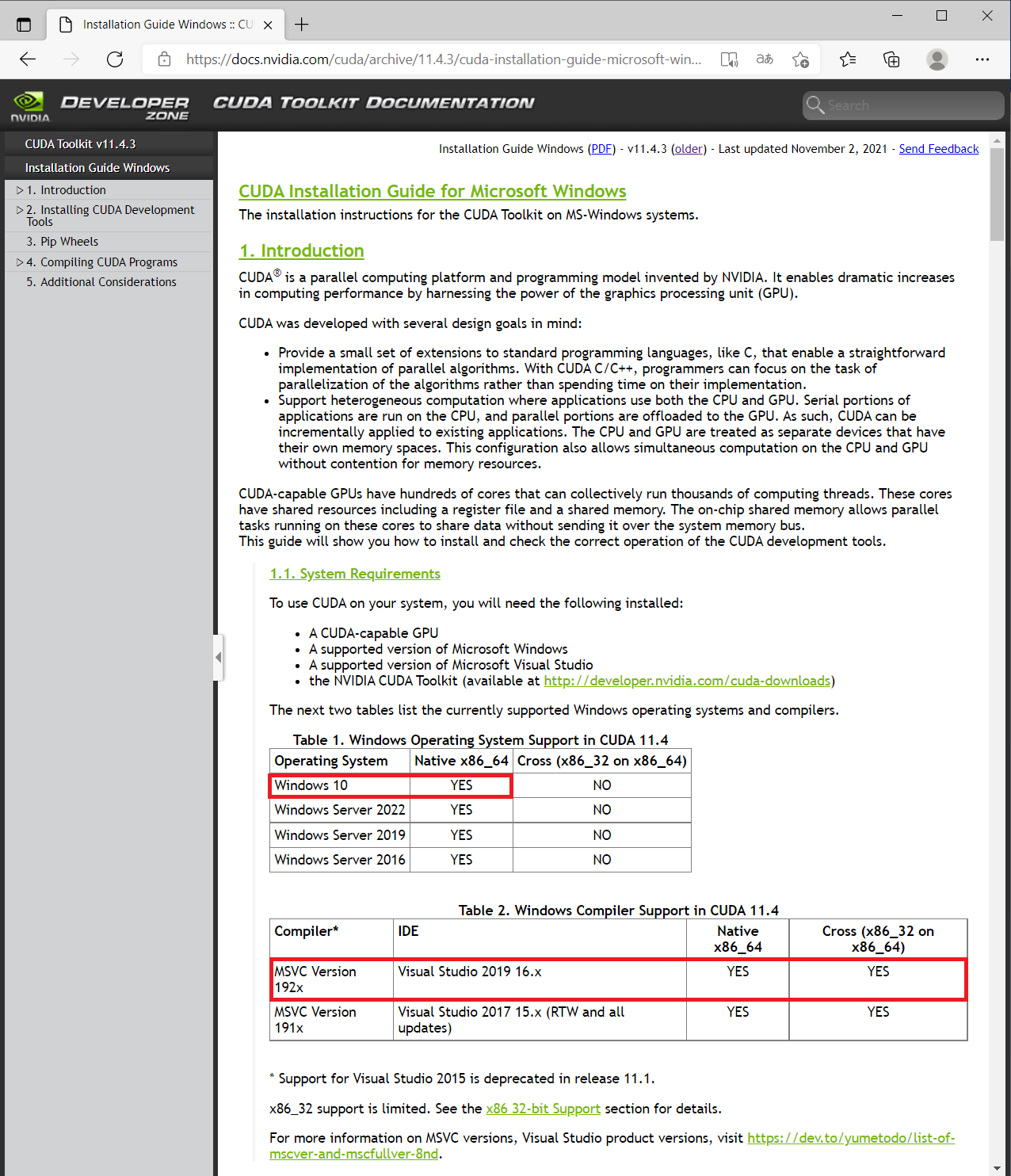
>>> print("Best Accuracy on training set = ", max(history.history['accuracy'])*100) Best Accuracy on training set = 99.94015097618103 >>> print("Best Accuracy on test set = ", max(history.history['val_accuracy'])*100) Best Accuracy on test set = 99.99518394470215
>>> print("Loss on training set = ", max(history.history['loss'])) Loss on training set = 0.3780692219734192 >>> print("Loss on test set = ", max(history.history['val_loss'])) Loss on test set = 0.018711965531110764
>>> history=classifier.fit(X_train, y_train, batch_size = 5, epochs = 300, validation_data=(X_test, y_test)) ValueError: Failed to convert a NumPy array to a Tensor (Unsupported object type float).
원인:
데이터가 float 뿐만 아니라 object가 섞여 있다.
numpy 는 오로지 숫자만 취급한다. pandas는 섞여 있어도 된다.
따라서, 데이터 전처리 시, 이미 df['Vis'] 를 0, 1로 바꾸고 number로 변환시킨 후, 데이터를 불러서 처리해야 한다.