신경망 구조
1. 네트워크(또는 모델)를 구성하는 층
2. 입력 데이터와 그에 대응하는 타깃
3. 손실함수: 예측과 타깃을 비교하여 모델의 예측이 기대값에 얼마나 잘 맞는지 측정하는 손실값을 만듬
4. 학습 진행방식을 결정하는 옵티마이저
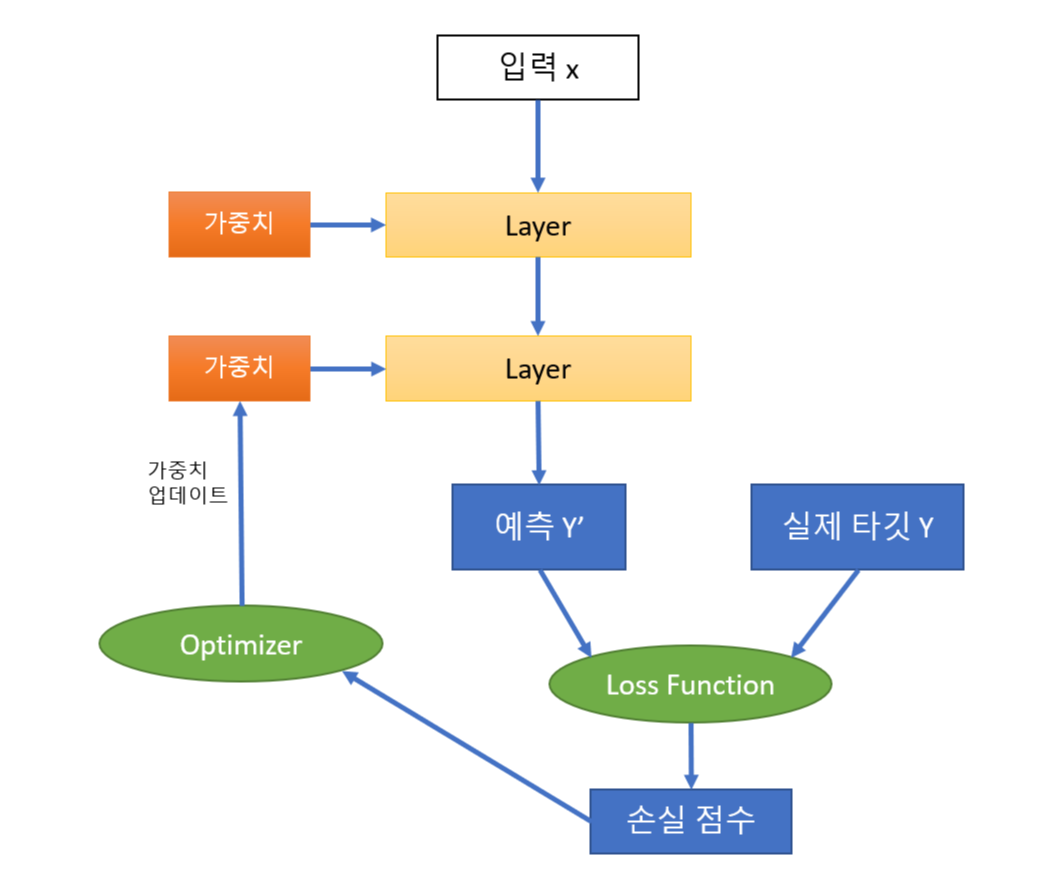
모델:
층의 네트워크
딱 맞는 네트워크 구조를 찾는 것은 과학보다 예술. 연습 필요.
>>> from keras import models
>>> from keras import layers
>>> model = model.Sequential()
Sequential() 모델의 경우, 단일 입력, 단일 출력인 경우 사용
다중입력 데이터 + 여러 딥러닝 모듈 인 경우 함수형 API 사용
모델 설정 - 층 설정
입력층, 은닉층, 출력층 등의 딥러닝의 구성 단위
하나 이상의 텐서를 입력받아 하나 이상의 텐서를 출력하는 데이터 처리 모듈
가중치: 대부분의 층은 가중치를 가짐. 네트워크(모델)가 학습한 지식이 가중치에 담겨 있음.
>>> model.add(layers.Dense(32, input_shape=(784,)) activation = 'relu')
첫번째 차원이 784인 2D텐서만 입력으로 받는 층을 만듬.
배치 차원인 0번째 축은 지정하지 않았기 때문에 어떤 배치 크기도 입력받을 수 있음
이 층은 첫번째 차원 크기가 32로 변환된 텐서를 출력함
즉, 이 다음 하위층은 32차원의 벡터를 입력으로 받는 하위 층으로 연결되어야 함.
(Kerase에서는 자동으로 층 호환성을 맞춤)
>>> model.add(layers.Dense(10), activation='softmax')
input_shape을 지정하지 않아도 Kerase에서는 자동으로 앞선 층의 출력크기로 맞춰줌.
컴파일 - 손실함수와 옵티마이저: 학습 과정을 조절하는 열쇠!
>>> from keras import optimizers
>>>model.comopile(optimizer = optimizers.RMSprop(r=0.001),
... loss='mse'
... metrics=['accuracy'])
손실(또는 목적)함수:
모델의 최적 매개변수(가중치, 편향) 학습에 필요한 에러 측정 함수
네트워크(망)이 예측한 결과와 데이터 세트에 명시된 실제 결과의 차이를 측정
훈련하는 동안 최소화될 값. 주어진 문제에 대한 성공 지표
손실함수 정의 방법:
분류문제: 데이터 세트의 데이터 중 잘못 분류한 비율을 계산하고, 그 비율을 에러 발생 확률로 사용
회귀문제: 입력 데이터로 예측한 결과와 실제 결과 간의 차이를 계산하여 평균을 구함.
옵티마이저 - 손실함수 최적화
손실 함수를 기반으로 네트워크가 어떻게 업그레이드 될 지 결정. 확률적 경사 하강법 사용해서 구함.
여러개의 출력을 만드는 신경망은 또한 여러 개(vector or tensor)의 손실함수를 가질 수 있음 (출력당 하나씩).
경사 하강법은 하나의 손실값(scalar)을 이용하기 때문에, 모든 네트워크에서 출력된 손실의 평균값을 계산.
신경망은 단지 손실함수를 최소화하기만 한다. 따라서, 목적 함수를 올바로 선택하지 않으면 원치않는 side effects가 커질 수 있다.
올바른 손실/목적함수 선택법:
1. binary_crossentropy (이항 교차 엔트로피 또는 이진 크로스엔트로피): 이진 분류 문제. 참/거짓 2개의 클래스를 분류할 때
2. categorical_crossentropy 범주형 크로스엔트로피: 여러개의 클래스 분류할 때
3. mean_squared_error 평균 제곱 오차: 회귀문제
4. mean_absolute_error 평균 절대 오차: 회귀문제
5. mean_absolute_percentage_error: 평균 절대 백분율 오차: 회귀문제
6. CTC(Connection Temporal Classification): 시퀀스 학습 문제
모델 실행 - 모델링 (fitting)
>>> model.fit(X, Y, epochs=100, batch_size=10)
일반적인 데이터 셋 csv 파일의 경우, 가로행(속성 또는 피쳐 feature), 세로열(샘플 또는 인스턴스instance 또는 example))로 구성됨.
Epochs
학습 프로세서가 모든 샘플 에 대해 한 번 실행되는 것을 1epoch
epochs=100 이면, 각 샘플이 처음부터 끝까지 100번 재사용될 때가지 실행을 반복하라는 뜻.
batch_size:
샘플을 한번에 몇개씩 처리할지 정하는 부분
batch_size=10 이면 전체 샘플 중 10개씩 끊어저 집어넣으라는 뜻.
너무 크면 학습도 저하, 너무 작으면 편차가 높아져 결과값이 불안정해 짐
따라서, 현재 시스템의 메모리가 감당할 만큼의 batch_size를 찾아 설정해 주는 게 관권.
모델평가
학습/테스트 세트로 구분하여 평가
과소적합/과적합