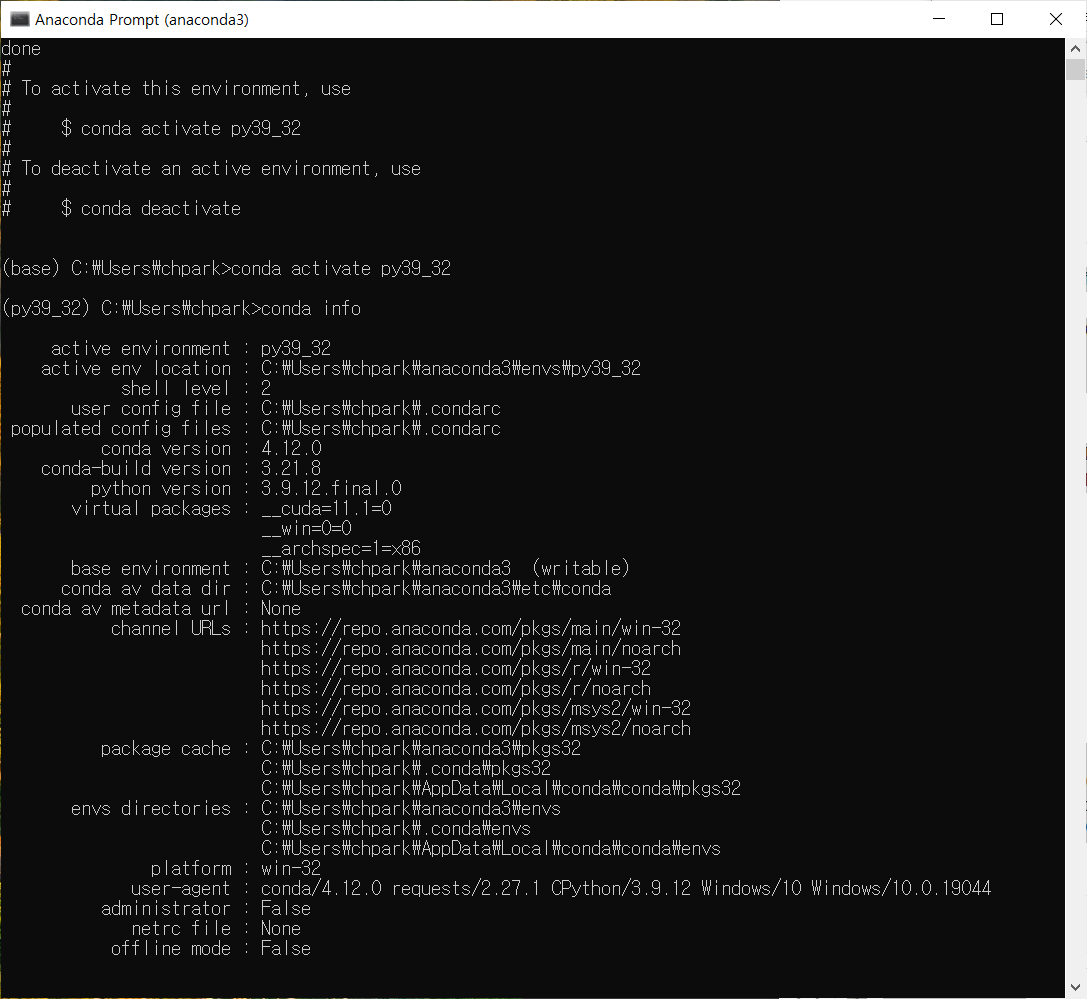
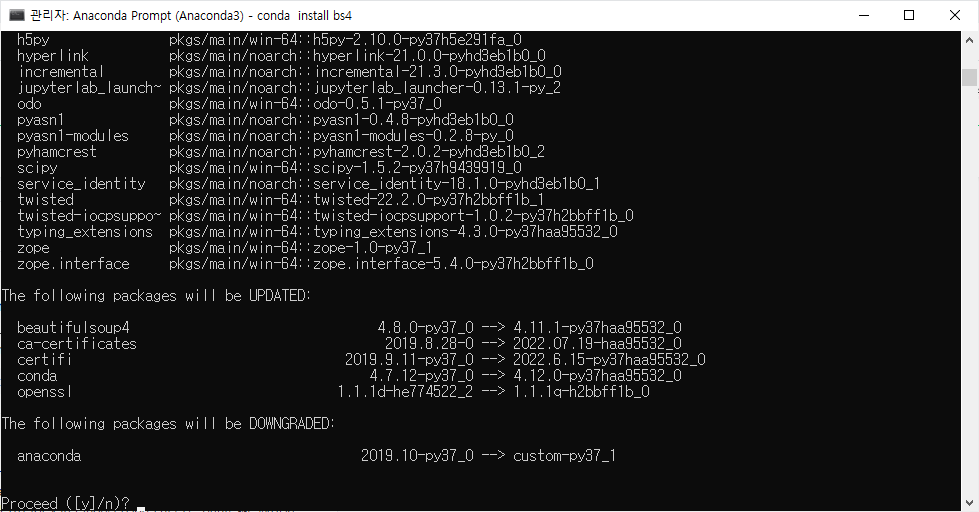
PC 등에서 공개 데이터(기상, 대기질, 증권 등)를 수집하기 위해서는 각 서버의 API를 사용해야 합니다. 이때, API 개발 환경의 bit 수를 맞춰줘야 합니다. 즉, 윈도우 OS Anaconda 64bit 환경에서 32bit API를 다룰려고 하면 Error가 발생합니다. 따라서, 아래와 같이 32-bit 개발 환경으로 변경하여야 됩니다. 이 방법의 장점은 아래와 같습니다.
1. 32bit 윈도우를 재설치할 필요없이 64bit 윈도우에서 개발 환경 설정 가능
2. 32bit 아나콘다 재설치 필요없이 64bit 아나콘다에서 개발 환경 설정 가능
방법
1. Anaconda Prompt 에서 아래 과정 수행
(base) C:\Users\chpark> conda --version
conda 4.12.0
(base) C:\Users\chpark> python --version
Python 3.9.12
(base) conda info
:
platform : win-64 로 확인됨.
:
2. 32bit 로 아나콘다 환경 변경
(base) C:\Users\chpark>set CONDA_FORCE_32BIT=1
위 명령을 수행하면 아무 반응이 없습니다. 주의할 점은 32BIT=1 사이에 공백이 없어야 합니다. set CONDA_FORCE_32BIT=0 를 입력하면 다시 64bit로 돌아옵니다. 아래와 같이 아나콘다 bit를 확인할 수 있습니다.
11.1 개요 (1) 지면은 습하거나 건조한 정도에 따라 태양열을 받아들이는 정도가 다르므로 지면온도의 상승 등에 영향을 주어 상층대기 구조에도 영향을 미치게 된다. (2) 지면상태는 다음과 같이 WMO Code 0901과 0975에 의해 관측한다. 11.2 관측 (1) 지면이 눈 또는 측정 가능한 얼음으로 덮여 있지 않을 때 0. 지표면이 건조(지면에 균열이 없으며, 모래 먼지는 일어나지 않음) 1. 지표면이 습윤함 2. 지표면에 물이 고여 있음(지표면에 크고 작은 물웅덩이가 생김) 3. 지표면에 유수가 있음 4. 지표면이 얼어있음 5. 지표면이 빙막으로 덮여 있음 6. 지표면은 건조된 먼지 또는 모래로 덮여 있으나 완전히 덮여 있지는 않음 7. 지표면은 건조된 먼지 또는 모래로 얇게 완전히 덮여 있음 8. 지표면은 건조된 먼지 또는 모래로 보통 또는 두껍게 덮여 있음 9. 지표면이 대단히 건조하여 균열이 있음 ※ 숫자부호 0~2와 4는 대표적인 맨땅에 적용하고 3 또는 5~9는 광범위한 지역에 적용한다. (2) 지면이 눈 또는 측정 가능한 얼음으로 덮여 있을 때 10. 지표면이 얼음으로 거의 덮여 있음 11. 지표면의 1/2 미만이 다져진 눈 또는 습성눈(얼음의 유무에 관계없이) 으로 덮여 있음 12. 지표면의 1/2 이상이 다져진 눈 또는 습성눈(얼음의 유무에 관계없 이)으로 덮여 있으나 완전히 덮인 상태는 아님 13. 지표면은 다져진 눈 또는 습성눈으로 균일하게 완전히 덮인 상태 14. 지표면은 다져진 눈 또는 습성눈으로 불균일하게 완전히 덮인 상태 15. 지표면의 1/2 미만이 푸석푸석한 건성눈으로 덮인 상태 16. 지표면의 1/2 이상이 푸석푸석한 건성눈으로 불균일하게 덮인 상태 (완전히 덮인 상태는 아님)17. 지표면이 푸석푸석한 건성눈으로 균일하게 완전히 덮인 상태 18. 지표면이 푸석푸석한 건성눈으로 불균일하게 완전히 덮인 상태 19. 지표면이 눈으로 두껍게 완전히 덮인 상태 ※ 광범위한 지역에 적용한다. ※ 눈 이외의 고체상 강수를 포함한다
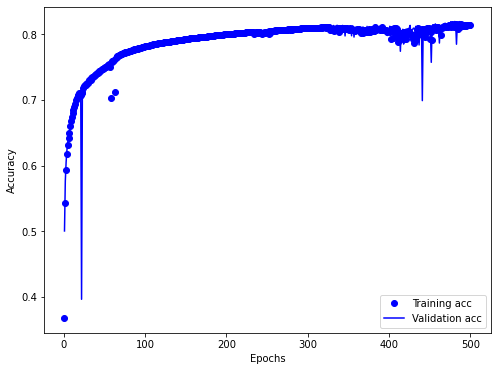
from keras import models from keras import layers from keras.callbacks import EarlyStopping from keras.callbacks import ModelCheckpoint # 모델 구성 _input_shape = X_train.shape[1] # input_shape : # of columns +1 _epochs = 500 # 모든 샘플에 대해 학습되는 횟수 _batch_size = 256 #512 # 샘플을 한번에 몇 개씩 처리할 지 결정. 전체 rows 를 _batch_size 만큼 끊어서 집어 넣어라. _patience = 200 _node_in = 16 # 입력층 노드 수 _node1 = 16 # 은닉층 노드 수 _node_out = 1 # 출력층 노드 수
model = models.Sequential() #은닉층을 차곡차곡 쌓는 방식의 모델이 sequential() model.add(layers.Dense(_node_in, activation = 'relu', input_shape=(_input_shape,))) # _input_shape 개의 입력값을 받아 은닉층 _node_in 개 노드로 보낸다는 뜻. model.add(layers.Dense(_node1, activation = 'relu')) model.add(layers.Dense(_node1, activation = 'relu')) model.add(layers.Dense(_node1, activation = 'relu')) # model.add(layers.Dense(16, activation = 'relu')) model.add(layers.Dense(_node_out, activation='sigmoid')) # 모델 컴파일 model.compile(optimizer = 'rmsprop', loss='binary_crossentropy', metrics=['accuracy']) ## optimizer = Adadelta, Adagrad, Adam, RMSprop, SGD # 모델 저장 폴더 생성 # MODEL_DIR = 'C:\Users\chpark\OneDrive\My_Code\L_Deeplearning\model_out' # if not os.path.exists(MODEL_DIR): # os.mkdir(MODEL_DIR) modelpath = 'C:/Users/chpark/OneDrive/My_Code/L_Deeplearning/model_out/{epoch:02d}-{val_loss:.4f}.hdf5' # 모델 업데이트 및 저장 checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss', verbose=1, save_best_only=True) # 학습 자동 중단 설정 early_stopping_callback = EarlyStopping(monitor = 'val_loss', patience=_patience)
from keras import models from keras import layers from keras.callbacks import EarlyStopping from keras.callbacks import ModelCheckpoint # 모델 구성 _input_shape = X_train.shape[1] # input_shape : # of columns +1 _epochs = 500 # 모든 샘플에 대해 학습되는 횟수 _batch_size = 256 #512 # 샘플을 한번에 몇 개씩 처리할 지 결정. 전체 rows 를 _batch_size 만큼 끊어서 집어 넣어라. _patience = 200 _node_in = 16 # 입력층 노드 수 _node1 = 16 # 은닉층 노드 수 _node_out = 1 # 출력층 노드 수
model = models.Sequential() #은닉층을 차곡차곡 쌓는 방식의 모델이 sequential() model.add(layers.Dense(_node_in, activation = 'relu', input_shape=(_input_shape,))) # _input_shape 개의 입력값을 받아 은닉층 _node_in 개 노드로 보낸다는 뜻. model.add(layers.Dense(_node1, activation = 'relu')) model.add(layers.Dense(_node1, activation = 'relu')) model.add(layers.Dense(_node1, activation = 'relu')) # model.add(layers.Dense(16, activation = 'relu')) model.add(layers.Dense(_node_out, activation='sigmoid')) # 모델 컴파일 model.compile(optimizer = 'rmsprop', loss='binary_crossentropy', metrics=['accuracy'])
# 모델 저장 폴더 생성 # MODEL_DIR = 'C:\Users\chpark\OneDrive\My_Code\L_Deeplearning\model_out' # if not os.path.exists(MODEL_DIR): # os.mkdir(MODEL_DIR) modelpath = 'C:/Users/chpark/OneDrive/My_Code/L_Deeplearning/model_out/{epoch:02d}-{val_loss:.4f}.hdf5' # 모델 업데이트 및 저장 checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss', verbose=1, save_best_only=True) # 학습 자동 중단 설정 early_stopping_callback = EarlyStopping(monitor = 'val_loss', patience=_patience)